这是来自WWW 2018的一篇关于通过相对路径覆盖来实现样式注入的论文——《Large-scale analysis of style injection by relative path overwrite》。
从题目就可以看出本篇论文是基于相对路径覆盖的样式注入的大规模分析。
简单介绍下Style Injection,样式注入,就是注入一段样式指令(css directives),因为浏览器在解析css资源内容的时候条件没有那么苛刻,导致浏览器解析了攻击者注入的样式指令。
Relative Path Overwrite这种攻击技术最早是Gareth Heyes在2014年的博客 http://www.thespanner.co.uk/2014/03/21/rpo/ 中提出的,这篇文章还额外指出某些版本的IE浏览器允许在兼容视图下从CSS上下文中执行JavaScript代码。
论文结构
论文从如下几个方面展开,所以这篇论文研读也会从如下几个方面展开:
- INTRODUCTION
- BACKGROUND & RELATED WORK
- METHODOLOGY
- ANALYSIS
- MITIGATION TECHNIQUES
- CONCLUSION
一、论文简介 Introduction
跨站脚本攻击(Cross-Site Scripting, XSS)一直是最常见的Web攻击之一,传统的XSS攻击就是攻击者将可执行脚本注入站点中,然后受害者的Web浏览器去执行这一段被注入的脚本,但是近期的研究表明,脚本攻击(Script Injection) 不一定就是有效攻击,在一定的条件下,通过注入构造好的CSS样式指令同样可以实现脚本攻击的效果。
脚本注入攻击通常是因为服务端对用户的输入没有进行充分地过滤,尽管脚本注入比基于样式注入的攻击有大的威胁,但是它们也更广为人知,并且Web开发人员会采取响应的措施使脚本注入更加困难。所以从攻击者的角度来说,如果很难或者无法进行脚本注入的情况下,不妨考虑下样式注入。
现在有不少将样式指令注入到站点中的技术:
- Scriptless Attacks - Stealing the Pie Without Touching the Sill
- Protecting Browsers from Cross-Origin CSS Attacks.
其中相对路径覆盖(Relative Path Overwrite)是一种方法,这是由Gareth Heyes在2014年的一篇博客中首次提出。
Motivations
- 近期的研究表明,脚本攻击不是有效攻击的必要前提,通过注入CSS指令,攻击者同样可以从站点中窃取信息。
- 与传统的XSS攻击相比,这种攻击方式(也就是样式注入)是最近几年才兴起的,而且不太为人所知。
- 尽管脚本注入攻击比基于样式攻击更强大,但是它们也更加广为人知,开发人员会在防御脚本攻击上下更大的功夫,反之攻击者就会将目光投向样式注入。
二、背景知识 Background
1.1 怪异模式(quirks mode)
参考自:https://blog.csdn.net/qq_31059475/article/details/78010601
浏览器解析CSS是有两种模式:标准模式(strict mode或是standard mode)和怪异模式(quirks mode),其实还有一种almost standards mode 。
标准模式 : 浏览器按照W3C标准解析执行代码;
怪异模式 : 这种模式主要是用来处理网络早期常见的一些编码不良的网站,浏览器使用自己的方式解析执行代码,不同浏览器解析和执行代码的方式不一样,所以称之为怪异模式。
浏览器在解析时使用标准模式还是怪异模式取决与网页中的DTD声明直接相关,DTD声明定义了标准文档的类型(标准模式解析)文档类型,会使浏览器使用相关的方式加载网页并显示。忽略了DTD声明,则会使网页用怪异模式解析网页,但这也不是唯一的情况,后面会介绍到当使用一些版本的DTD声明也会使浏览器进入怪异模式。
DTD声明 : 由于HTML有很多版本的规范,每个版本的规范都有差异,为了让浏览器能够正确编译渲染网页,需要在网页的第一行告诉浏览器,当前的网页是用的哪一个版本的规范。声明文档规范在网页行首添加如下代码即可:
1 |
这两种模式解析css的差别就在于,在怪异模式下,浏览器将会忽视文档中Content-Type:text/html等声明文档类型的描述,将其中的任何css解析执行,反之如果是位于标准模式下,浏览器将只解析Content-Type:text/css的内容,其余的会报错。
浏览器在渲染网页时是使用标准模式还是怪异模式,与网页中的文档类型声明直接相关。
这里用两个简单的例子来分别解释一下浏览器渲染页面这个两种方式。
1 | // code [1] |
1 | // code [2] |
这两段代码的区别就是code [2]包含一个doctype声明。
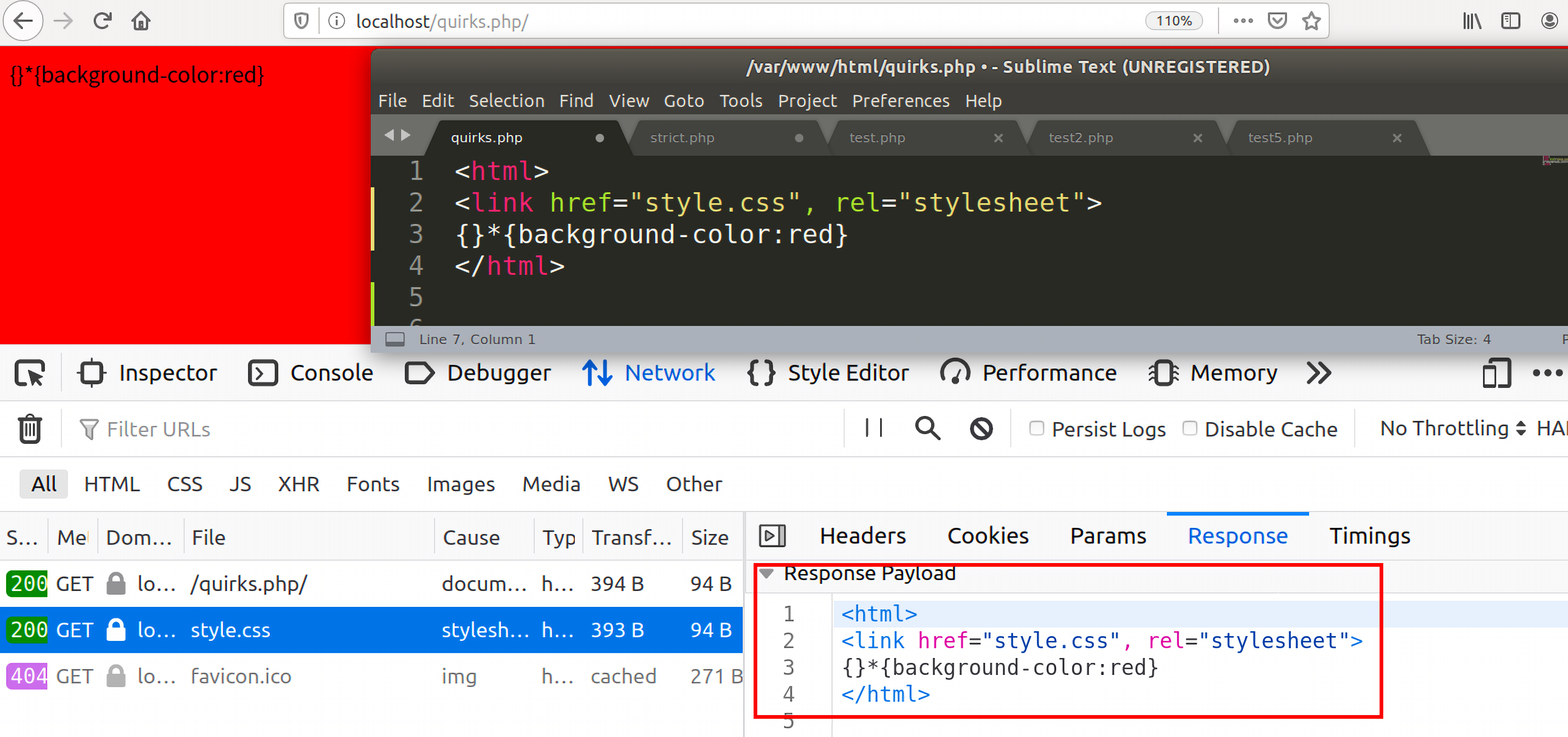
我们发起的请求是http://localhost/quirks.php/,后面需要再跟上一个路径分隔符/。
对于服务器来说,它知道这个请求其实就是http://localhost/quirks.php,所以针对这个请求,服务器会返回一个如下图所示的response:
这个结果和我们期望的结果是一致的,返回了一个与quirks.php文件对应的html文档。
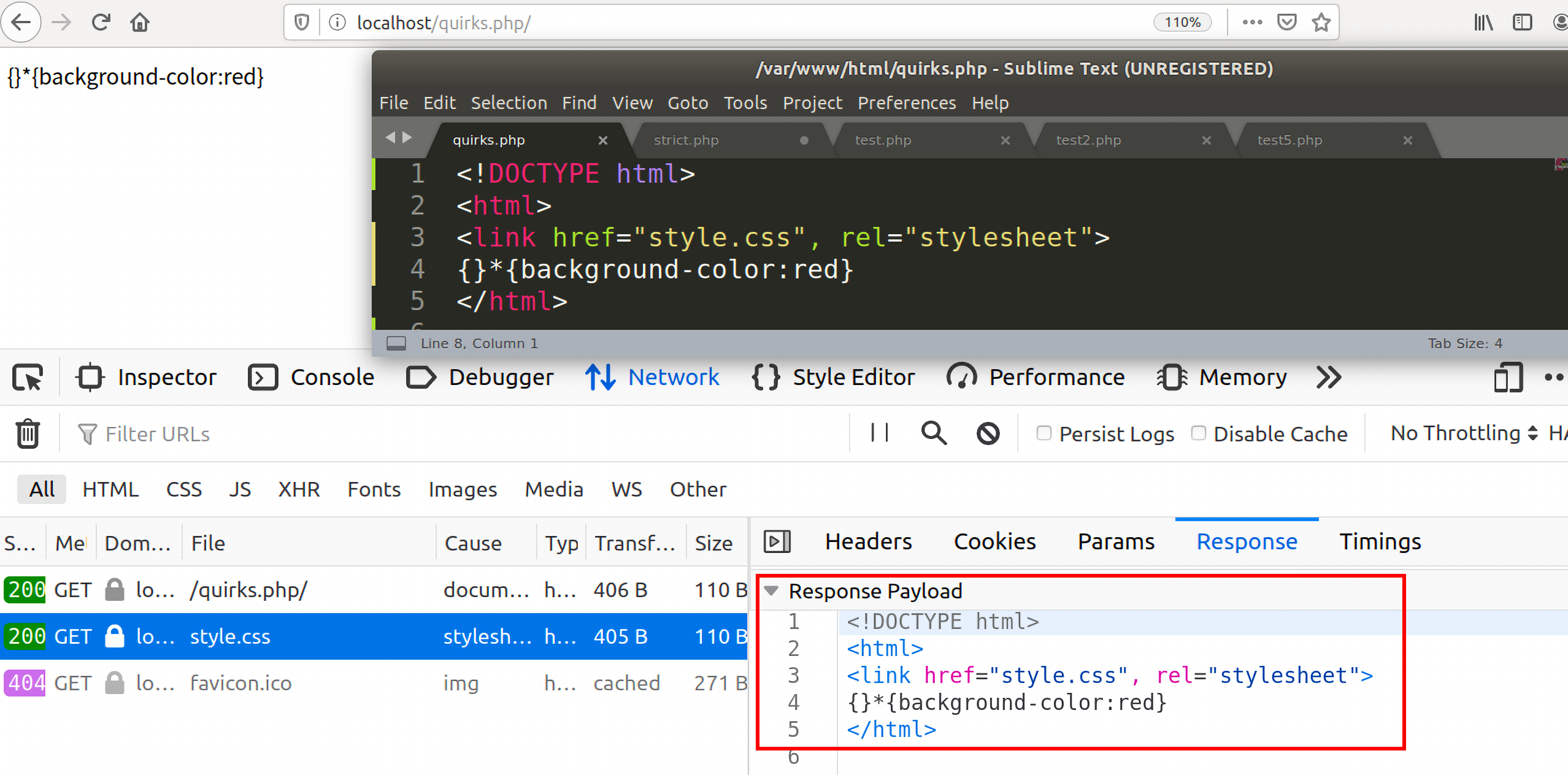
但是因为quirks.php中还包含了style.css文件,所以它还会去请求这个css文件,此时经过浏览器拼接后就变成了http://localhost/quirks.php/style.css,注意,这里浏览器没有服务器那么聪明,我们发起的原始请求是http://localhost/quirks.php/,浏览器就认为quirks.php/是一个目录,所以经过拼接,浏览器对css的请求路径就变成了下图所示情况:
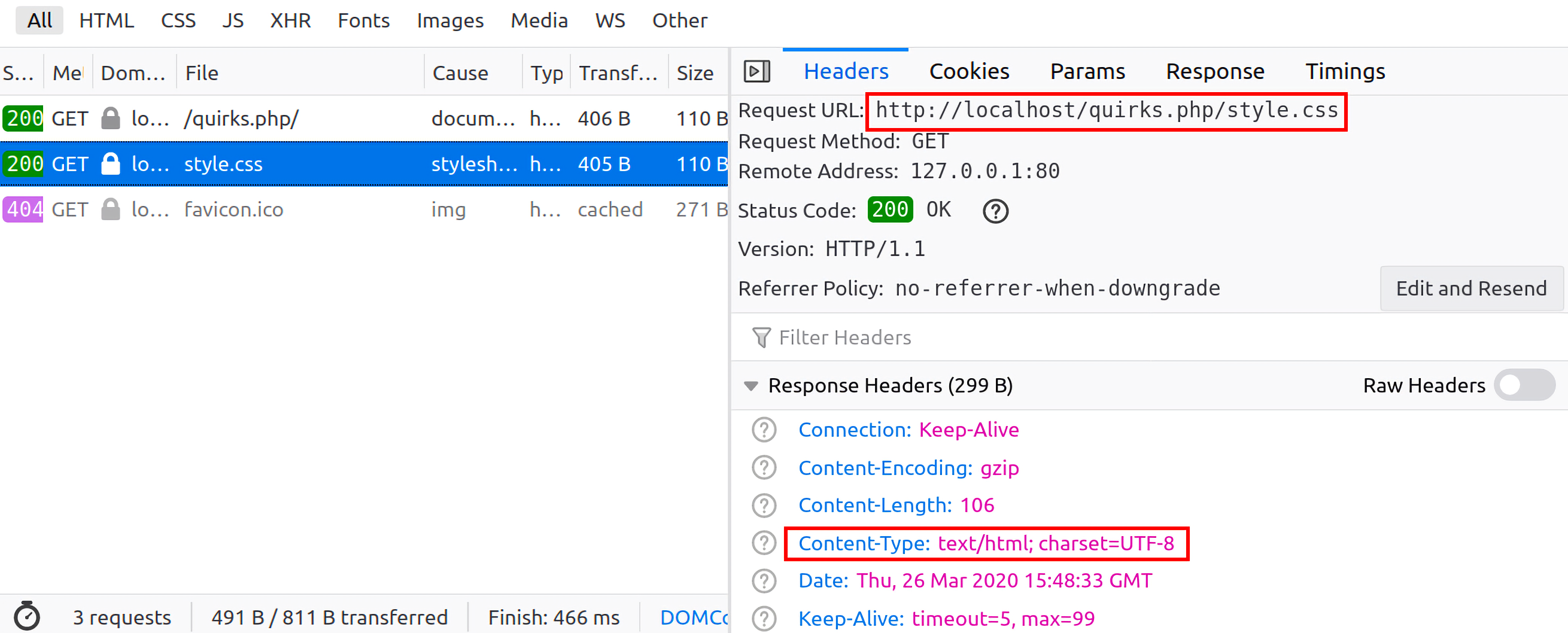
返回的response中的Content-Type被浏览器推断为html/text,内容如下图所示:
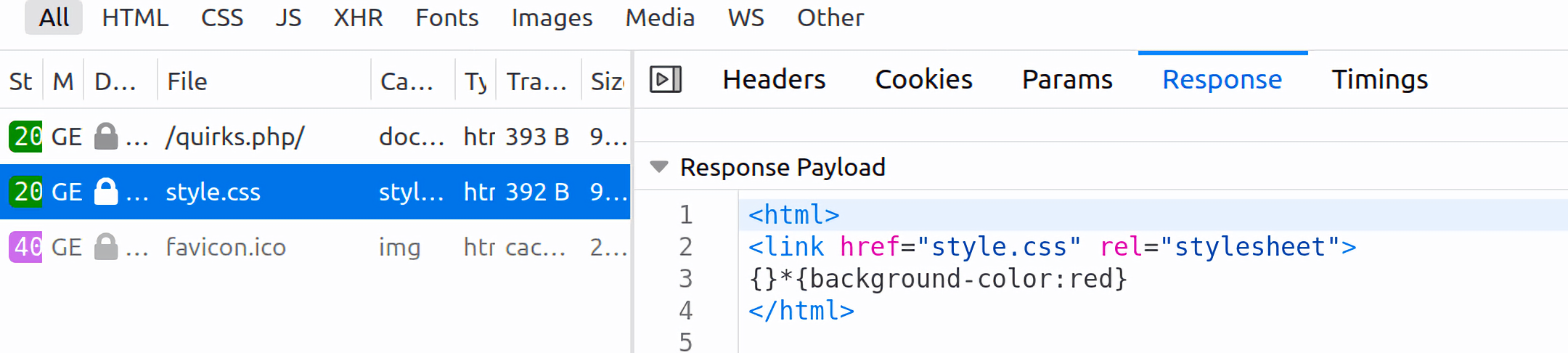
可以看到返回的response内容竟然和quirks.php是一模一样的,这里的原因在后面的RPO中解释。
对于这个例子,我们需要了解的就是,因为没有声明doctype,所以浏览器用quirks mode来渲染我们的页面,在quirks.mode下,浏览器会忽略其中html/text等文档类型声明,将其中的任何css指令执行。
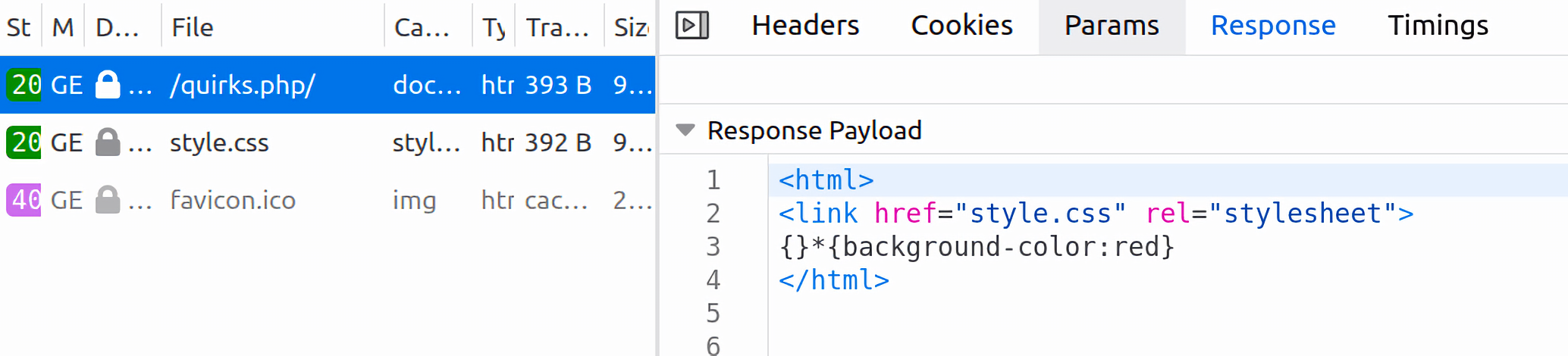
当存在一个正确的doctype声明时,浏览器只会去解析Content-Type:text/css的内容,对于其他类型的css文件,会报一个error:
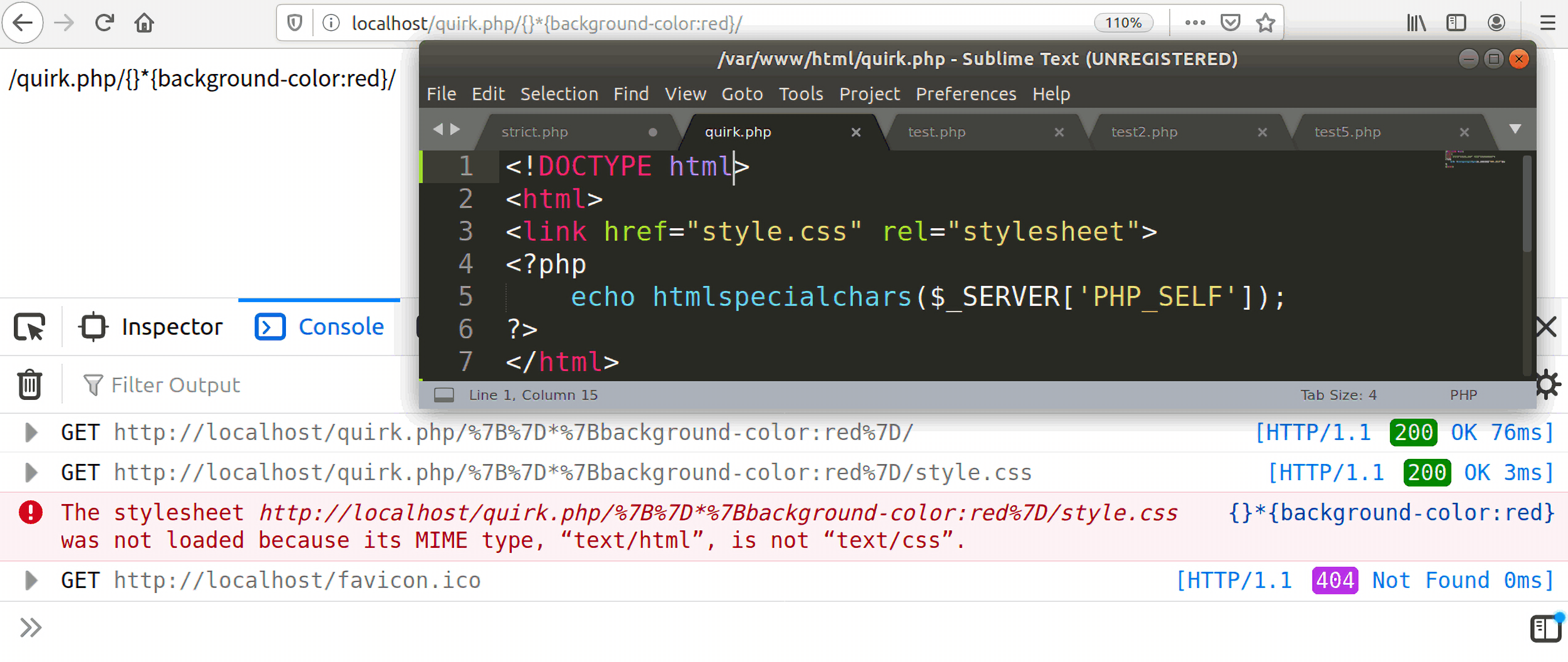
所以说quirks mode是样式注入攻击成功的必要条件。
1.2 相对路径覆盖 Relative Path Overwrite
RPO利用的方式有很多,而在这篇论文中,作者是使用RPO来进行样式注入。
下面用一个简单的例子来介绍下如何利用RPO来进行样式注入。
首先是一个victim php文件,其中用相对路径引入了一个style.css文件,style.css文件中的内容是什么并不重要,事实上我在测试的时候这个文件并不存在,因为我们的目的并不是让浏览器去解析这个style.css文件,我们的目的是让浏览器去解析被我们改造后的css文件。
1 | <html> |
这里$_SERVER['PHP_SELF']表示当前php文件相对于网站根目录的位置,与document root相关。
这个攻击可以分成三步来理解:
- 攻击者发起一个这样的请求:
1 | http://192.168.247.131/quirk.php/{}*{background-color:red}/ |
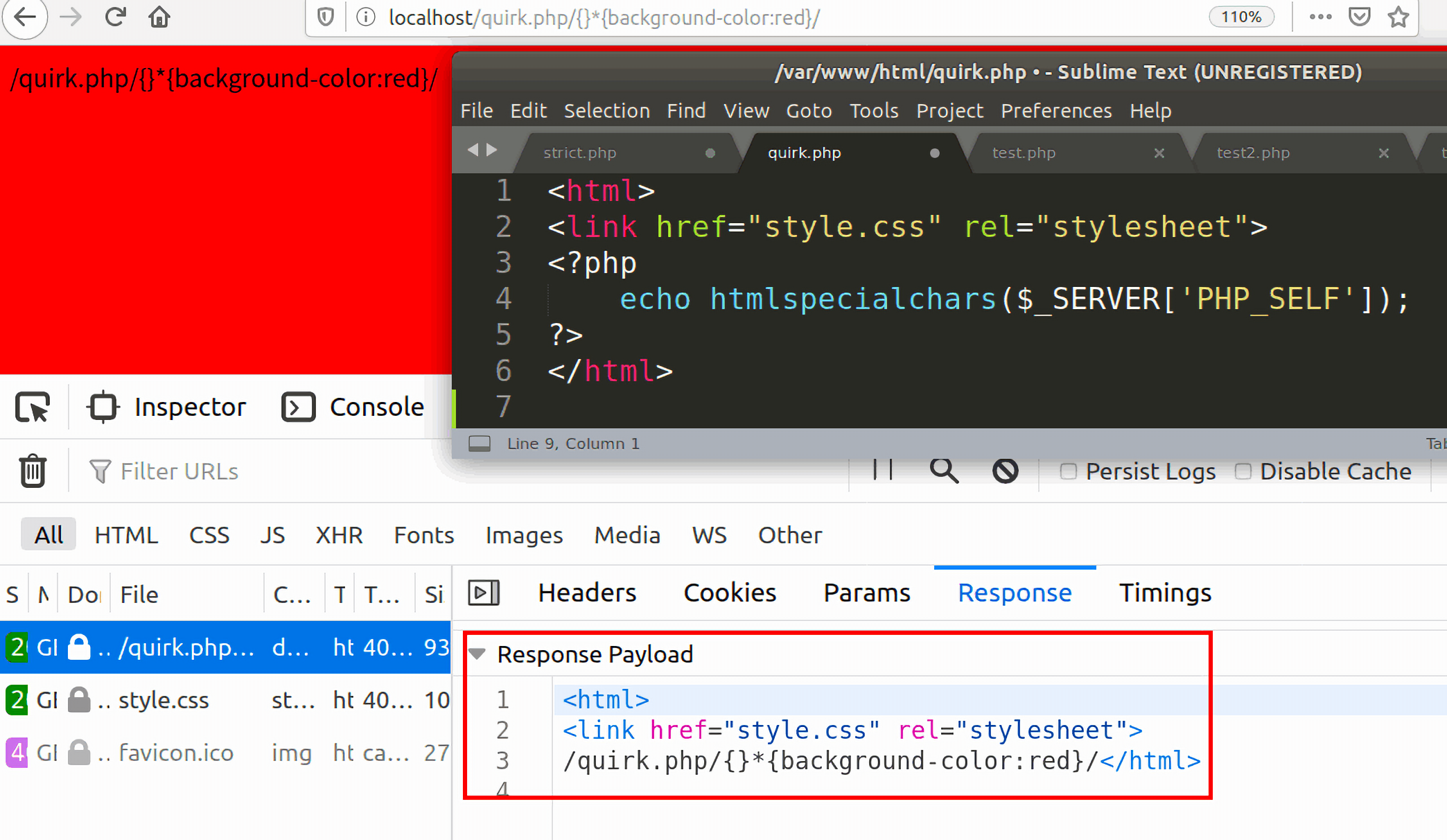
下图是服务器返回给浏览器的response内容。
- 因为页面中还包含一个css文件,所以浏览器还会去请求这个css文件。
如果这个css文件是用绝对路径引入的,那么浏览器就会去这个路径指定的位置去取这个css文件,当但如果这个文件不存在,返回的就是一个找不到文件的错误。
但是这个文件是用相对路径引入的,所以浏览器经过拼接后,它向服务器去请求这个css文件,请求路径为:
1 | http://localhost/quirk.php/{}*{background-color:red}/style.css |
相比于它原来的路径,这个css文件的路径被overwrite了。
- 对于浏览器的这个请求,服务器交给
quirk.php来处理,服务器认为后面的{}*{back-ground-color:red}/style.css是quirk.php的相关参数,所以quirk.php将自己的文档内容当作style.css的内容返回给客户端:
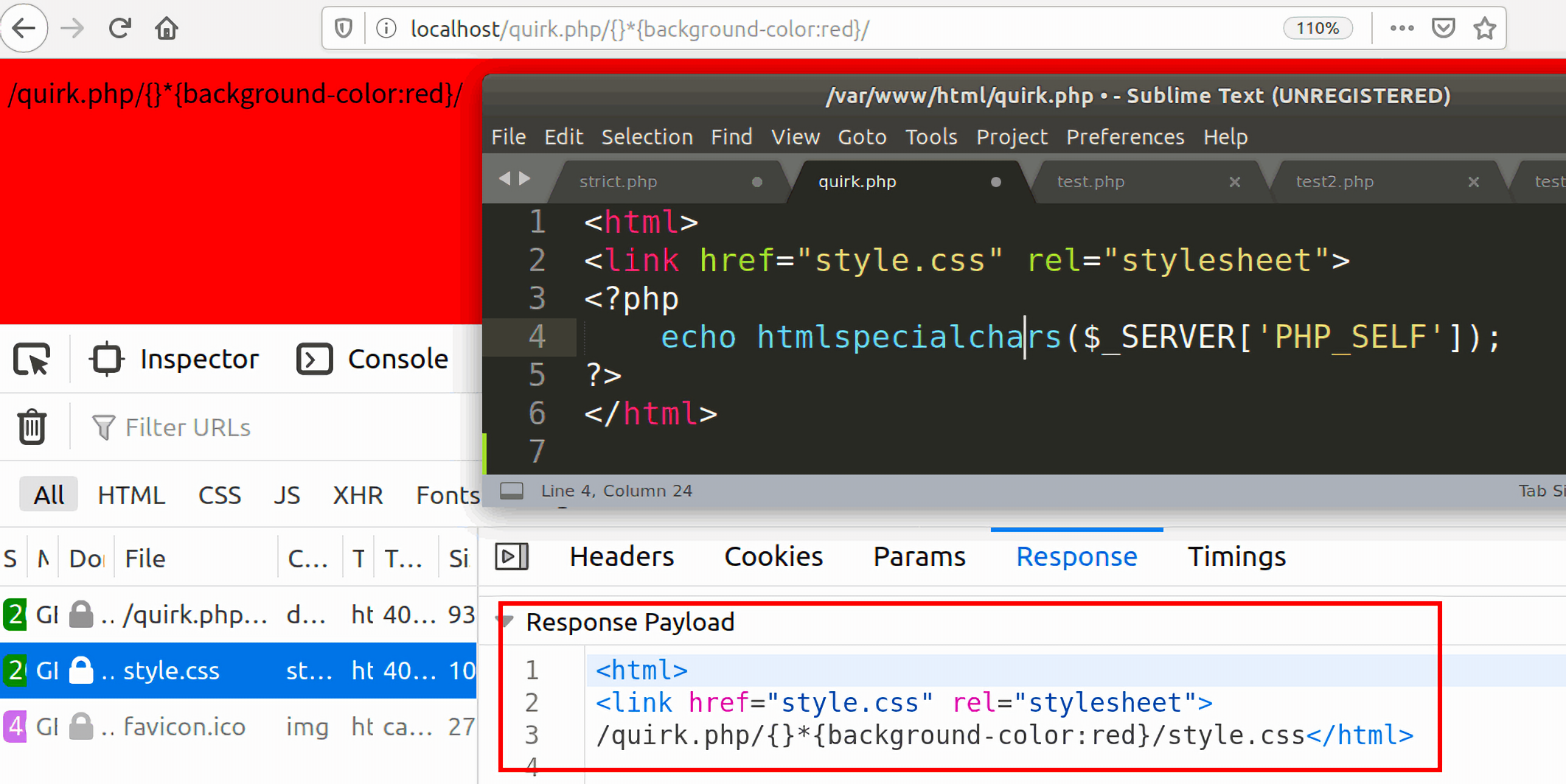
以上就是利用RPO进行样式注入的原理。
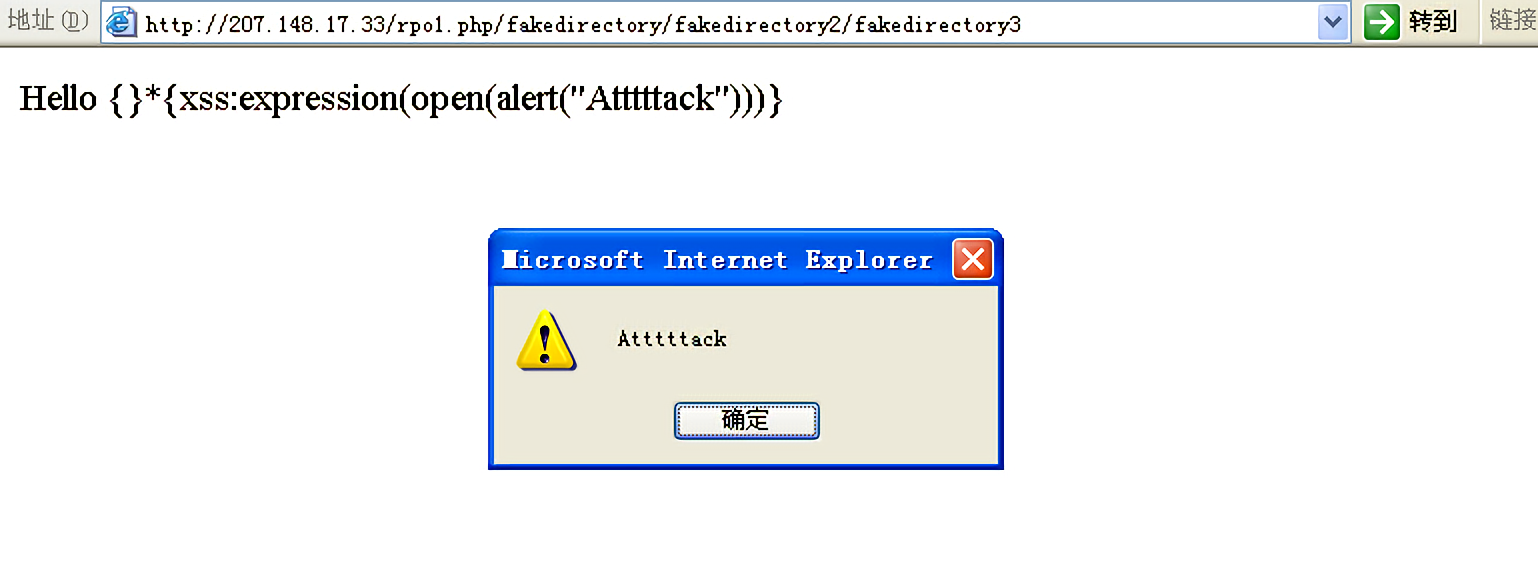
在IE的一些旧版本中还可以用expression()命令来执行一些xss命令,如下图是在IE6中进行的测试:
1 | <html> |
效果如下图所示:
1.3 RPO样式注入的先决条件
如果要成功进行RPO样式注入,那么页面需要满足下面的这些条件
- 该页面包括至少一个使用相对路径的样式表,这样才能重写样式表的请求路径
- URL重写,比如对于下面这个请求:
1 | http://example.com/test/view.php/anything/here?f=2 |
如果服务器不支持url重写,浏览器就会让here去处理这个请求,而不是我们期望的view.php。
- 页面能够回显注入URL或是Cookie中的样式指令(回显可以在页面内的任意位置中);
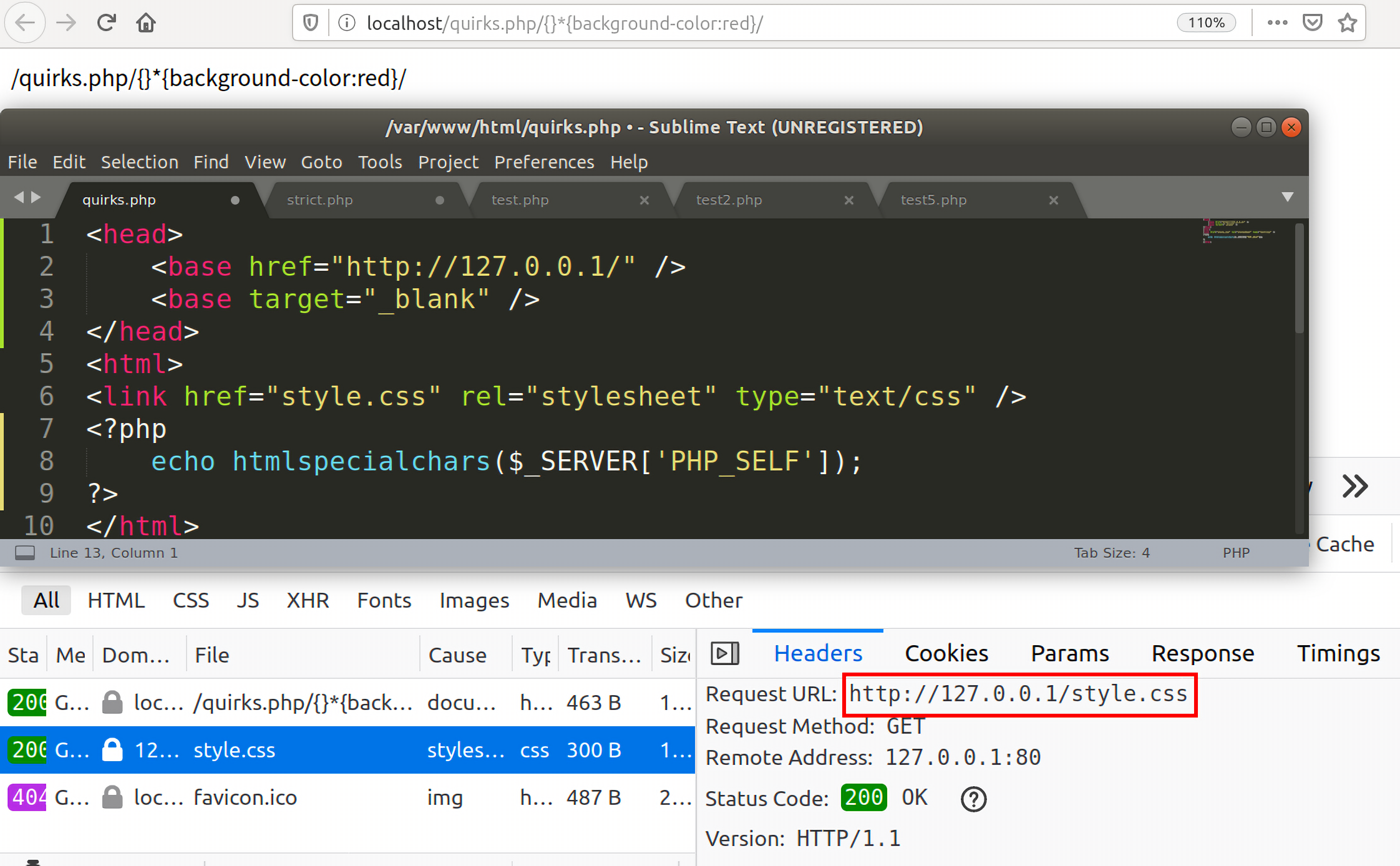
- 在相对样式路径之前不包含
<base>标签。
<base>标签是会为页面上的所有链接规定默认地址或者是默认目标,比如有如下代码:
1 | <head> |
此时我们再用之前的payload去攻击,已经无法生效了。
简单理解,RPO漏洞就是服务端和客户端对URL解析的不一致导致的。
三、实验方法 Methodology
本篇论文中的实验主要分为三个步骤:
- 从 Common Crawl网站上下载普通的爬行归档的页面,提取出其中至少包含一个样式表的候选页面。
- 为了确定这些候选页面是否容易遭受到攻击,作者会尝试注入一些css样式指令,方法是请求的url能够引起path confusion,来测试生成的响应页面是否能够生成我们注入的指令。
- 最后,实验测量了一些易受攻击的页面有多少是能成功在浏览器中被真正利用的,标准就是检查在Web浏览器中是否成功解析了注入的样式指令。
3.1 Candidate Identification
数据集是来自 Common Crawl在2016年8页爬取下来的、包含1.6亿个页面的存档。使用现有数据集的好处就是可以快速识别候选页面,不会消耗任何Web爬行流量。
然后用一个Java HTML parser来过滤一些仅包含内联CSS或者是CSS是通过绝对路径嵌入的网页。
内联CSS也被称为行内CSS或是行级CSS,是指直接在标签内部引入的CSS。
1 | <body> |
经过上面这一步筛选,最后剩下2亿300万个网页,分别来自600万个站点。
为了实验的可测量性,这里作者又进行了进一步的筛选,分成两个步骤来进行:
- 仅保留Alexa(一个网站排名网站)中排名前100万的站点页面,这样能让评估结果更加倾向于流行的站点,因为那些站点访问者的数量多,Relative Path Overwrite攻击能产生更大的影响,这一步就将候选页面的数量减少到了22.3万网站的1亿4000万个页面
- 第二步是对网站进行分组处理,将那些具有相似url和相同文档类型的页面分成一组,在后面进行测试时只需要从中选取代表就可以,比如下面这两个url就会被归为同一组:
经过上面这些处理,最后的数据集包含来自22万个网站的1亿3千7百万页面
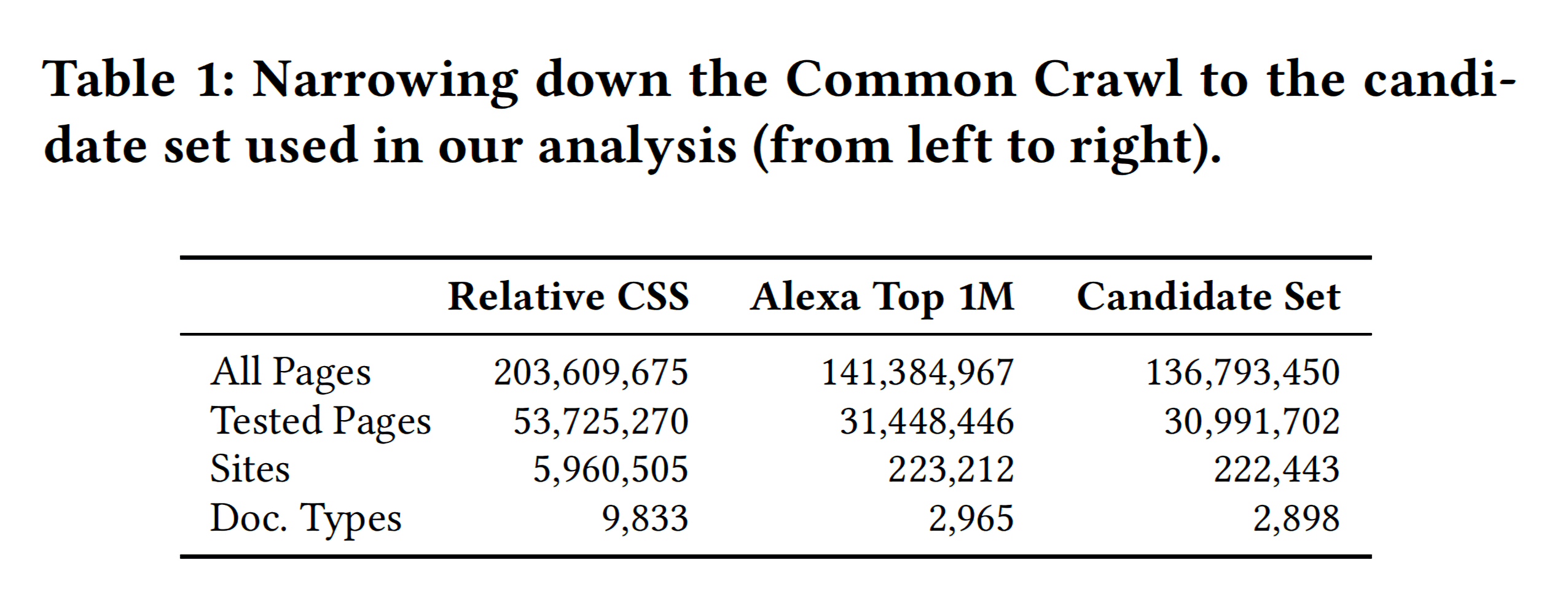
上表就是论文中用到的数据集,其中Tested Pages就是指从页面组中随机选择的一组页面。
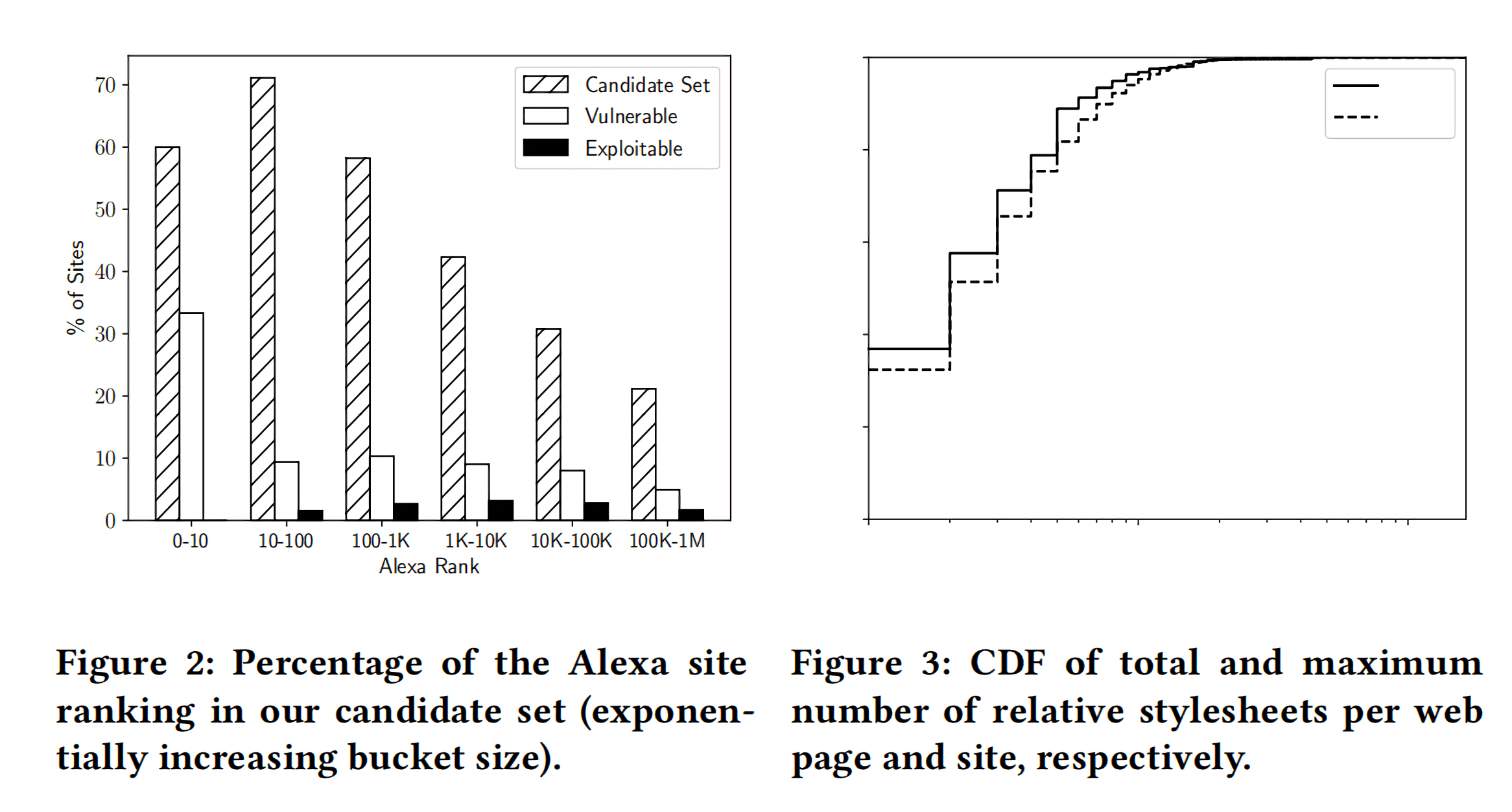
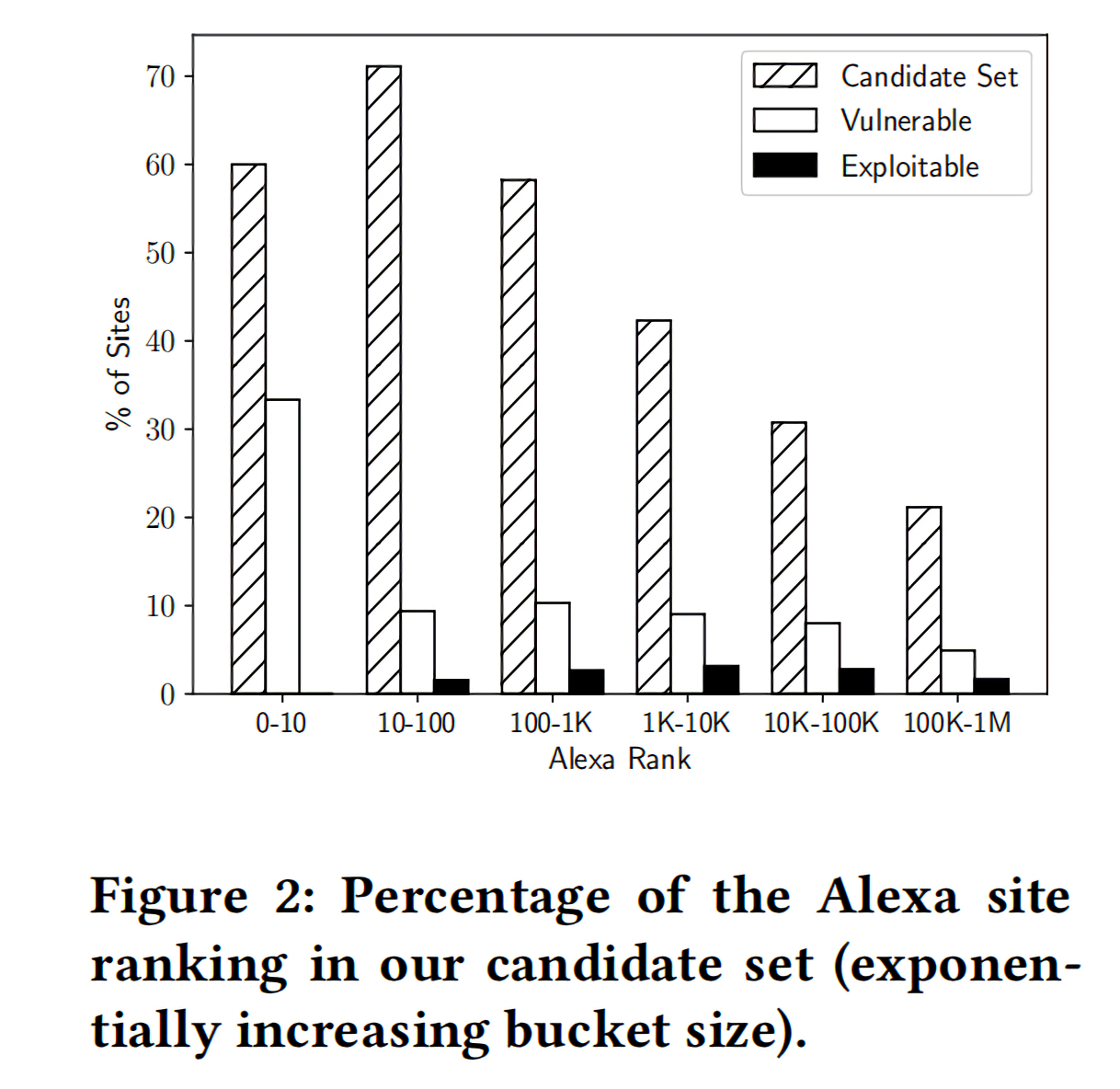
下面的Figure 2是候选集中站点的流行度占比情况。Figure 2中的阴影条,也就是第一列,是数据集中流行站点的覆盖情况。比如,10个最大的站点中有6个在候选集合中,并且包含相对样式路径。从图中可以看出,实验的候选集包含较高比例的流行站点和较低比例的非流行站点,这能保证实验的结果更能反应流行站点的RPO漏洞存在情况。
Figure 3表示虽然候选集中的所有页面至少包含一个相对样式路径,但其中有63.1%的页面包含多个相对路径,这增加找到样式注入点的机会。
3.2 Vulnerability Analysis
为了找出存在潜在风险的页面,也就是(Vulnerable Pages),作者分了以下几步完成:
- 实现一个基于Python Requests模块的轻量的crawler;
- 从上一步数据集筛选分组后的页面中选出一个代表页面进行注入
- 构造能造成path confusion,路径混淆的URL进行注入;
- 得到了服务器的response之后,查找response中是否存在
标签,如果包含就认为这个页面是安全的;如果不存在,爬虫会从响应中提取所有相关的样式表路径,并以主页mutate之后的URL为基础展开它们,就是模拟浏览器处理url的方式; - 请求每个唯一(NONCE是随机的)的stylesheet URL,直到找到一个反映响应中存在注入的样式指令为止
下图就是生成path confusion的方式:

上图中的每一组都由三个URL组成,第一个URL表示的是正常请求下的URL;第二个URL是Attacker构造过的URL,假设每个HTML页面都会引用一个样式表(../style.css),浏览器在解析stylesheet路径时会像第三个URL一样进行解析。其中PAYLOAD是一串类似%0A{}body{background:NONCE}的一串字符,加入%0A是因为作者发现它能提高注入的成功率。
图(a)显示了一个通用示例,其中URL中不包含query string或是path parameter。
图(b)和图(c)其实差不多,这里区分开表示是因为不同的Web框架对path parameter的处理略有不同,这种情况可以根据正则表达式匹配来区分,比如PHP和ASP用/斜杠来分隔path parameter,而JSP用;分号来分隔path parameter。当正则表达式匹配到这些时,它会将payload注入参数中。
图(d)是对URL中的/符号进行了编码,编码为%2f,这主要是因为像Ngnix和配置错误的Apache浏览器能将URL的%2f解码为/,而浏览器却不会将%2f解码。
图(e)其实和图(d)差不多,只不过是对query string中的?进行了编码,编码后为%3f。
图(f)中的Cookie,作者认为如果攻击者可以创建新的Cookie或是篡改现有的Cookie(与其他技术相比,这是一种强有力的假设),并且在相应页面中能够反应Cookie的值,那么应当可以向Cookie中注入Payload来实现样式注入攻击。
咨询了飘零师傅后,飘零师傅表示对于measurement类的文章,需要搞懂它是如何进行大规模测试,所以在这里补充的两点。
一,因为候选集网页中的样式表路径可能会包含一些父级目录(比如../../../../style.css),浏览器在将样式表相对路径扩展到父目录的时候可能会从url中删除掉payload,所以在实际应用中,crawler会附加20个/符号来避免不同数量级的父目录;
二,因为不同的框架对path parameter的处理略有不同,这种情况前面也已经说到,可以根据正则表达式的样式匹配来区分,比如PHP和ASP会用/来分隔path parameter,而JSP是用;来分隔path parameter。当crawler用正则匹配到这些的时候,就会将payload注入到这些参数中去。所以它其实是根据不同的url生成具体的exp来请求。
3.3 Exploitability Analysis
经过上面一步(Vulnerability Analysis)经过Python Crawler挑选出Vulnerable的页面之后,还需要在Chrome浏览器进行进一步实验,看看这些页面在真实的浏览器上是否能被攻击。因为一个能否能够被exploit是被多种因素影响的,比如如果HTML页面使用的是现代文档类型,那么浏览器就不会用怪异模式来渲染页面,而我们知道,成功的exploit需要浏览器进入怪异模式。
出于这个目的,作者建立了一个基于Google Chrome的crawler,并用Remote Debugging Protocal去驱动浏览器并且记录响应的HTTP请求和响应。
从上一步中抓取了所有至少存在一个反射的页面进行样式指令注入。
样式指令使用随机生成的图像URL来为HTML主体页面加载背景图像,通过检查是否有向外部请求img图像的HTTP请求流量来判断样式指令注入是否成功。为了防止注入失败,会在payload前面填充很多个}或者是]用来闭合页面源码中存在的{或者[。
最后作者在Internet Explorer浏览器中重复了在Chrome浏览器中相同的实验。
3.4 Ethical Consideration
为了尽量减少在我们被注入的CSS被存储的情况下的破坏性副作用,被注入的CSS不是一个有效的样式指令,所以即使它被存储在服务器上,它也不会对页面有任何可见的影响。作者做了以下这些出来来避免对网站的伤害:
- 并不登录网站;
- 不提交任何表单;
- 为了避免触发JavaScript events,并不点击页面中的任何按钮或链接。
四、实验结果评估
文章从三个方面进行了评估,并在网站对应的一些CMS应用程序中发现了漏洞。
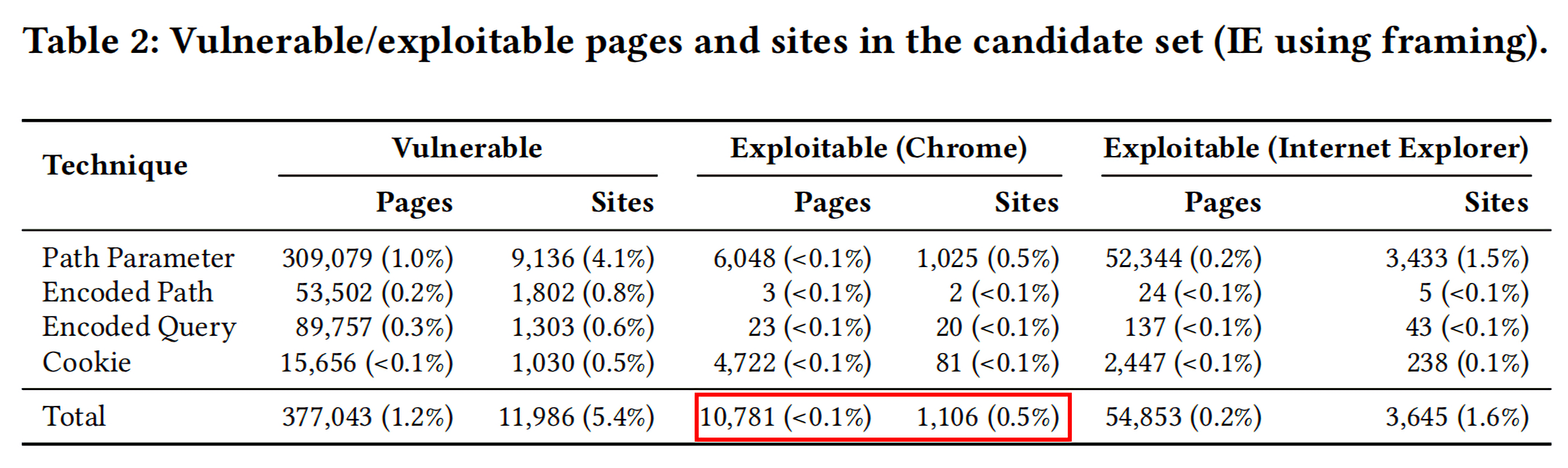
先来看一下总体情况,Table 2是实验的一个总体情况,
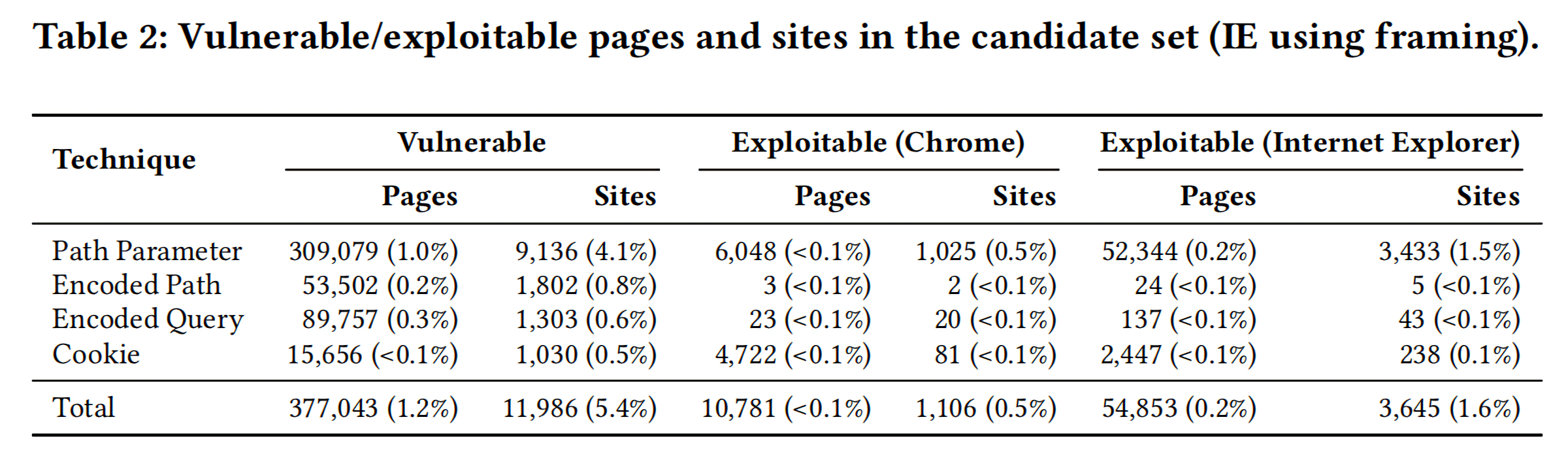
- 在所有的数据集中,有1.2%的页面存在至少一个Vulnerable页面,影响的站点数量占所有网站的5.4%;
- 通过向Path Parameter中注入payload是最有效的方式;
- 在候选集中存在2.9%可以被exploit的Vulnerable页面,0.5%的站点存在至少一个可以被恶意利用的页面;
- 在所有易受到攻击的页面中,有14.5%的页面在IE中是可以被exploit的,这个数据是在Chrome浏览器中的5倍之多。
4.1 Vulnerable Pages
只要前面提到的几种样式注入中有成功的(服务器的响应能成功反映Payload的注入),那么就认为这个页面是Vulnerable的。
实验发现,站点呈现出的情况就是:
- 排名越高,越容易存在漏洞;
- 在Alexa排名前10的站点中候选集中包含6个,其中这6个站点中有2个站点是存在Vulnerable页面的;
- 候选集主要是由Alexa中排名10万到100万的小站点组成,这些站点的vulnerability rate在4.9%,降低了整个数据集的平均水平。
此外为了保险起见,作者认为响应中应当不包含<base>标签,因为服务端正确配置后的<base>标签能够防止path confusion。
我们已经知道页面中<base>标签能够防止path confusion,因为它能够指示浏览器如何扩展相对路径,但是在实验中发现了它的初衷和它的使用上的不同之处。作者发现在候选集中的60个网站上包含一个<base>标签,但是,注入Payload之后服务器的响应不再包含<base>标签,这就意味着<base>标签无法起到它原始的效果了。
此外,作者还发现了Internet Explorer在<base>标签的实现上可能存在问题。当出现<base>标签后,Internet Explorer能根据相对样式路径展开两个URL,一个根据标签中指定的基本URL展开,另一个则以path confusion的方式展开。在作者的实验中,Internet Explorer最后应用的样式表URL总是path confusion的,即使根据<base>标签生成的URL更快被加载。所以作者认为<base> 标签在IE浏览器中无法有效地防御RPO攻击(在Edge浏览器中能正常工作)。
4.2 Exploitable Pages
为了测试一个Vulnerable的页面有多少属于Exploitable,也就是易受攻击页面中有多少是可以被利用的,作者在Chrome中打开这些页面,并注入一个带有图像(随即生成的URL)引用样式的payload,并检查图像是否确实被加载。
从上图可以看到,在候选集中存在2.9%可以被利用(Exploitable)的Vulnerable页面,0.5%的站点存在至少一个可以被恶意利用的页面。
然后作者探讨了各种可以使Vulnerable页面被Exploit的因素:
4.2.1. Document Types
前面已经提到过,HTML document types在基于RPO的样式注入攻击中起着很重要的作用。实验中的候选集页面总共包含4318个不同的文档类型。这些独特的文档类型(Document Types)大多不是标准化的,它们与标准化(strict mode)的文档类型只有很小的变化,比如拼写错误或是忘记空格。
为了确定浏览器如何解析这些文档类型(以及确定它们会不会导致浏览器以标准模式或者怪异模式来解析页面),作者又设计了一个对照实验(Controlled Experiment):
- 对于每一个唯一的文档类型,设置一个具有相对样式表路径的本地页面,然后使用前文提到的payload来进行RPO样式注入攻击;
- 分别在Chrome、Firefox,Edge,Internet Explorer,Safari和Opera中打开该本地页面,然后查看哪一种文档类型解析了被注入的CSS样式,以及下载了注入的背景图像。
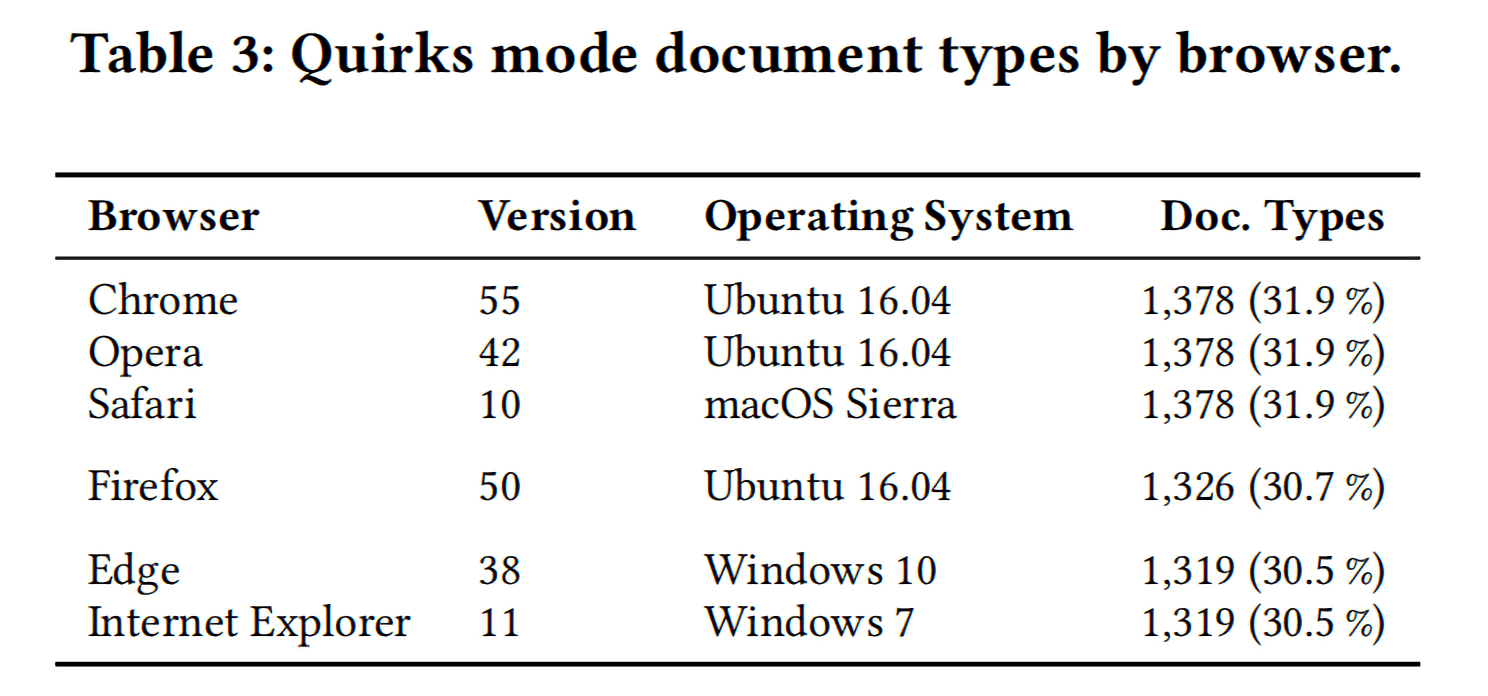
上表Table 3是实验的结果,可以看到尽管浏览器之间的确切数字有点不同,但是上述的这些4318种文档类型中,对于每种来浏览器来说,都会有大约三分之一的文档类型会导致浏览器以怪异模式解析本地页面。
Edge和Internet Explorer都是微软的产品,所以它们的结果是一样的;Chrome、Opera和Safari的测试结果也一样,这是因为它们的webkit都一样。总体来说,29.4%(1271种)的文档类型会导致所有浏览器进入怪异模式,31.9%(1378种)的文档类型会导致至少一个浏览器进入怪异模式。

上表Table 4显示了会使所有浏览器都进入怪异模式的最常用的文档类型,包括一些页面中没有声明文档类型的。
这告诉我们并不是在html页面中添加一个DTD声明就能解决所有问题,一些老旧的文档类型会使所有的浏览器都进入怪异模式,在 https://hsivonen.fi/doctype/ 就列出了这些文档类型:
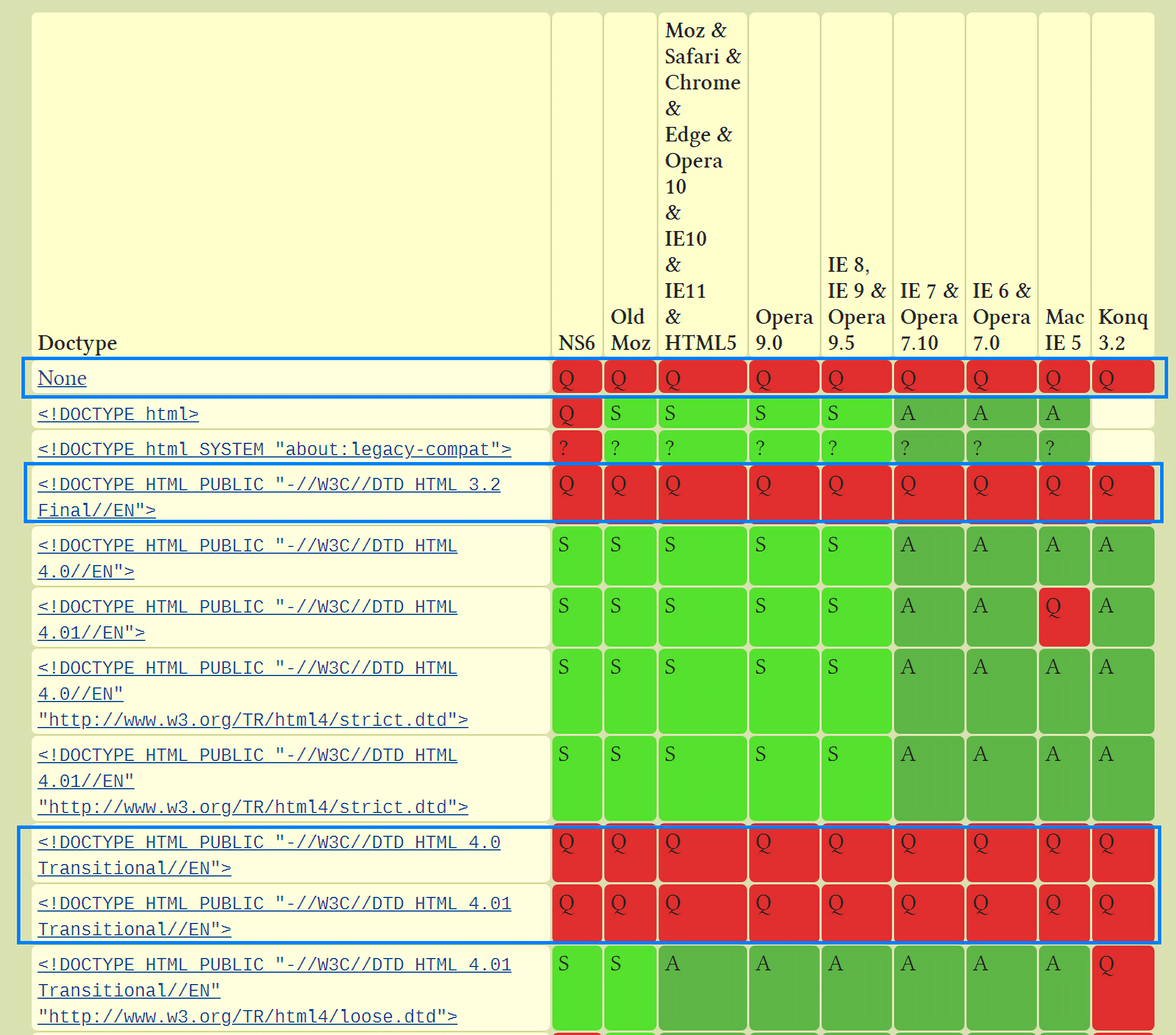
还要注意有一些情况下(来自维基百科 https://zh.wikipedia.org/wiki/%E6%80%AA%E5%BC%82%E6%A8%A1%E5%BC%8F ),DOCTYPE的语法可能会无效,比如下面这个例子:
1 |
因为它包含公共标识符关键字PUBLIC,但是却没有指示所用的HTML版本名称,也没有HTML文档类型定义的系统标识符URL(系统标识符就是http://www.w3.org/TR/html4/strict.dtd),这也会触发怪异模式。
还有一个例外是在IE 6下,如果DTD声明之前有一个xml声明,那么无论是否指定完整的DOCTYPE,它都会用quirks模式来渲染一个页面:
1 |
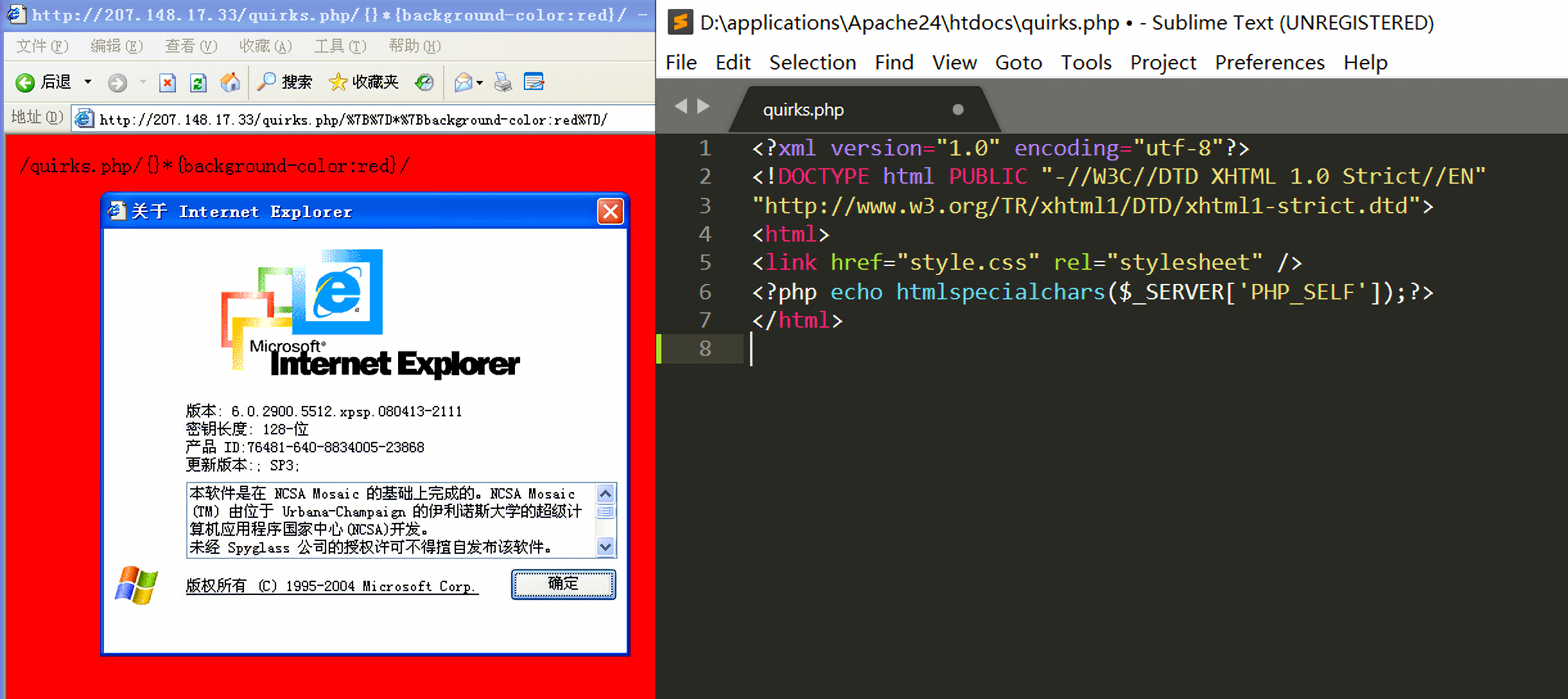
另一个例外是,如果DOCTYPE之前有任何的语句,quirks模式会在IE 9及其之前的任何浏览器中触发quirks模式:
1 | <!-- This comment will put IE 6, 7, 8, and 9 in quirks mode --> |
在Internet Explorer 6中实验后发现确实会触发quirks模式:
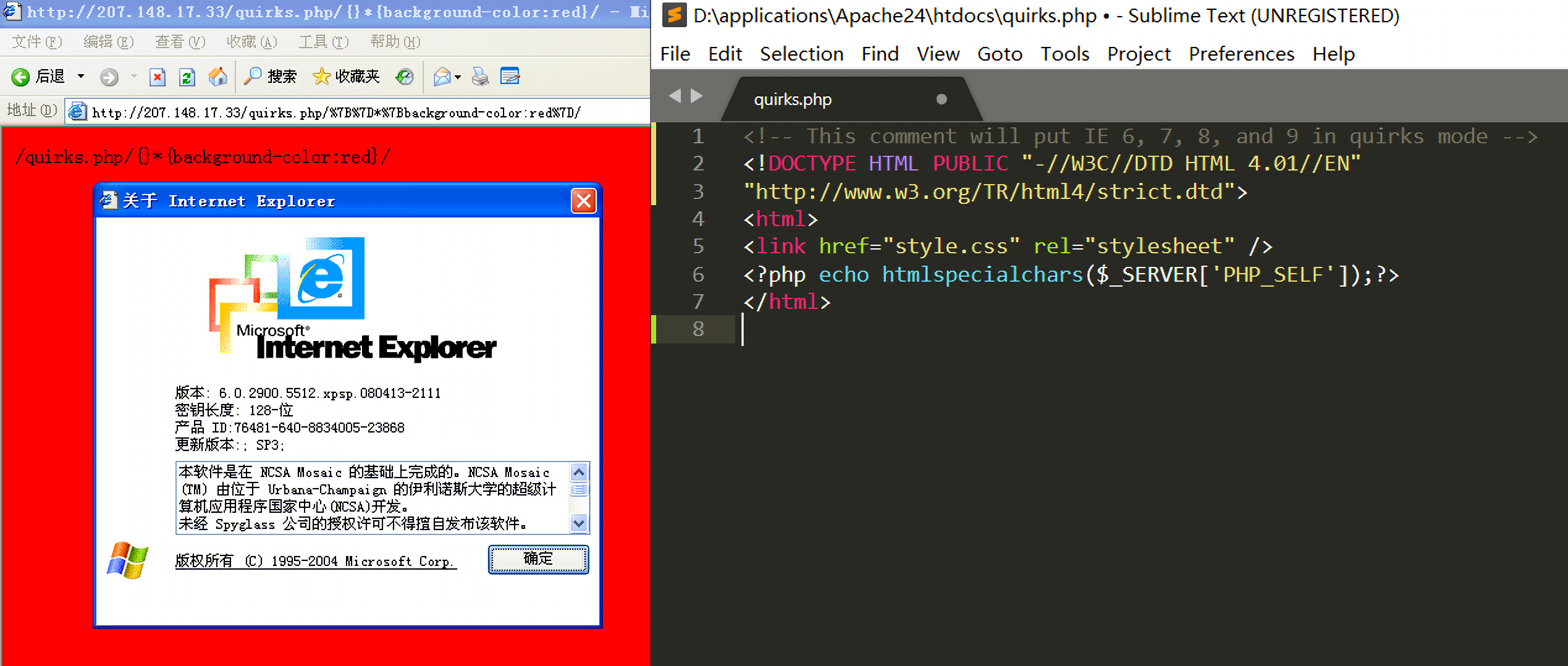
相同的代码对Chrome浏览器就没效:

4.2.2 Internet Explorer Framing
这是针对IE浏览器的,IE浏览器在frame中加载页面时,IE浏览器会忽略其中的标准文档类型声明,作者在IE浏览器中复现了相同的实验后,发现14.5%的vulnerable页面在IE中是可以被exploit的。
4.2.3 Anti-Framing Techniques
因为IE浏览器中存在的framing问题,作者又探讨了Anti-Framing技术,有一个http响应头字段与之相关:X-Frame-Options。这个字段告诉浏览器是否要加载一个iframe中的页面,为了防止rpo攻击,最好是将这个字段的值设置为deny。
实验发现,在Vulnerable的数据集中,391个站点的4999个页面正确地使用了这个报头,从而防止了攻击,但是34个站点上的1900个页面提供了不正确的X-Frame-Options值,作者用Internet Explorer在2个网站的552个页面上进行了成功的攻击。
4.2.4 MIME Sniffing
最后一个影响因素就是MIME协议。
互联网上的资源有各种类型,通常浏览器会根据响应头的Content-Type字段来分辨它们的类型。例如:”text/html”代表html文档,”image/png”是PNG图片,”text/css”是CSS样式文档。然而,有些资源的Content-Type是错的或者未定义。这时,某些浏览器会启用MIME-sniffing来猜测该资源的类型,解析内容并执行。
比如在实验中,服务器返回的fake stylesheet,因为不确定它们的类型是什么,浏览器是用MIME-sniffing来猜测该资源的类型为text/html,而在怪异模式下,text/html类型的文档中包含的样式指令也会被解析
为了让浏览器禁用MIME Sniffing并且不对错误的文档类型进行解析,服务器可以在响应中加入以下响应头:
1 | X-Content-Type-Options: nosniff |
它在PHP中可以这样设置:
1 | header("X-Content-Type-Options:nosniff"); |
实验发现,在vulnerable数据集中,232个站点进10万个页面正确的使用了这个字段,10个站点中的23个页面在Chrome浏览器中是可以被exploit的,但是在IE浏览器中却不行,这是因为Chrome浏览器并没有遵守这个协议。
4.3 Content Management System
在分析统计数据集中可以被RPO攻击利用的页面时可以发现很多页面都是属于一些知名的CMSes。由于这些CMS应用程序通常会被安装在很多个站点上,所以修复这些应用程序中的RPO漏洞就是一件有意义的事情。
为了识别这些页面是来自什么CMS,作者用Wappalyzer访问了所有可以被攻击利用的页面。在这个过程中,还检测到了两个不被Wappalyzer支持的CMS。总的来说,最后作者在1589个站点的41288页面中发现了23种不同的CMS。
但是这些RPO攻击点弱点的成因是否来自CMS本身还无法确定,所以作者通过安装这些CMS的最新版本(或是online demo)来调查这些攻击点是否来自于CMS本身。方法就是测试在数据集中发现的可利用路径是否在CMS中也是可用的。经过分析,最后发现在4个CMS(最新版本)中是可以成功复现RPO攻击的,这4个CMS又在1197个站点中被使用,影响到了40225个页面。
除了实验中用到的数据集以外,Wappalyzer还在Internet上检测到这些CMS有将近32K的安装,这表明有更多的站点可能会存在RPO漏洞。
五、应对策略 Mitigation Techniques
针对这种攻击方式,文中提出了一些防御措施:
- 抛开其他杂七杂八的方法,最有效的莫过于不使用相对URL,直接使用绝对路径,Relative Path Overwrite简单来说就是因为服务端和浏览器对于URL解析存在差异导致的,所以如果在HTML页面中只使用绝对路径,这样就不需要浏览器来扩展相对路径了;
- 在页面中使用
<base>标签,当HTML页面中包含一个<base>标签时,浏览器将使用其中提供的URL来扩展相对路径,而不是通过解析当前文档的URL来扩展相对路径,当然前提是服务器端要正确配置; - Web开发人员可以通过消除任何可以被解释为样式指令的字符串来减少攻击伤害。但是其实这种方法很难完全实现,比如用户上传一张看似无害的个人资料图片,其中就可以包含攻击脚本或是样式表
- 规范使用DTD文档声明,这样HTML文档就会以标准模式呈现,这种防御方式对绝大多数的浏览器生效(Internet Explorer除外);
- 针对IE浏览器,Web开发人员可以在响应头中设置一些字段,比如X-Content-Type-Options(禁用content type sniffing);总是使用服务发送的MIME type(当然前提是配置正确);X-Frame-Options字段设置禁止在frame中加载页面;用X-UA-Compatible字段设置关掉IE浏览器的兼容视图。
六、局限性 Limitations
- RPO是一类攻击,作者的方法只涵盖其中的一部分;
- 文章中挖掘的漏洞都是反射型(Reflected)的CSS样式注入,而不是存储型(Stored)的样式注入。
- 相比于用爬虫批量查找RPO漏洞页面,人工查找可以发现更多的注入风格或方式。
- 为了提高效率,作者使用的是现有的Common Crawl上的数据集,不会分析没有包含在该数据集中的页面,这就意味着无法覆盖所有的的站点,也不会完全覆盖站点内的所有页面。
七、创新点 Contributions
- 这是第一个对现实网络站点中存在的RPO漏洞进行大规模自动化分析的实验;
- 文章讨论了一系列攻击影响因素,并提出了一些防御措施 讨论了一系列攻击影响因素,并提出了一些防御措施;
- 最后一点是作者还在很多cms中发现了相关rpo漏洞,并且通知了相应的厂商。
八、总结 Summary
本篇论文中的实验并没有什么很困难的技术难点,实验方法就是利用爬虫来对每个页面进行分析,但本篇论文的亮点就在于它展示了现实网络站点中可能会受到的RPO攻击影响的一种情况。
RPO作为一种新型的Web攻击方式,本文的作者是利用它来进行样式指令注入,css的语法要求没有那么严格,允许很多脏字符的存在,并且即使有不符合css语法的地方,也会被浏览器忽略,继续向下执行,直到找到合法的css语句。与之相比,注入js脚本就困难得多了,因为js有更严格的语法要求,并且不能包含脏字符,但同时,如果能找到一种注入js脚本的方式,造成的危害也会更大,这也可以成为我们未来研究的方向。