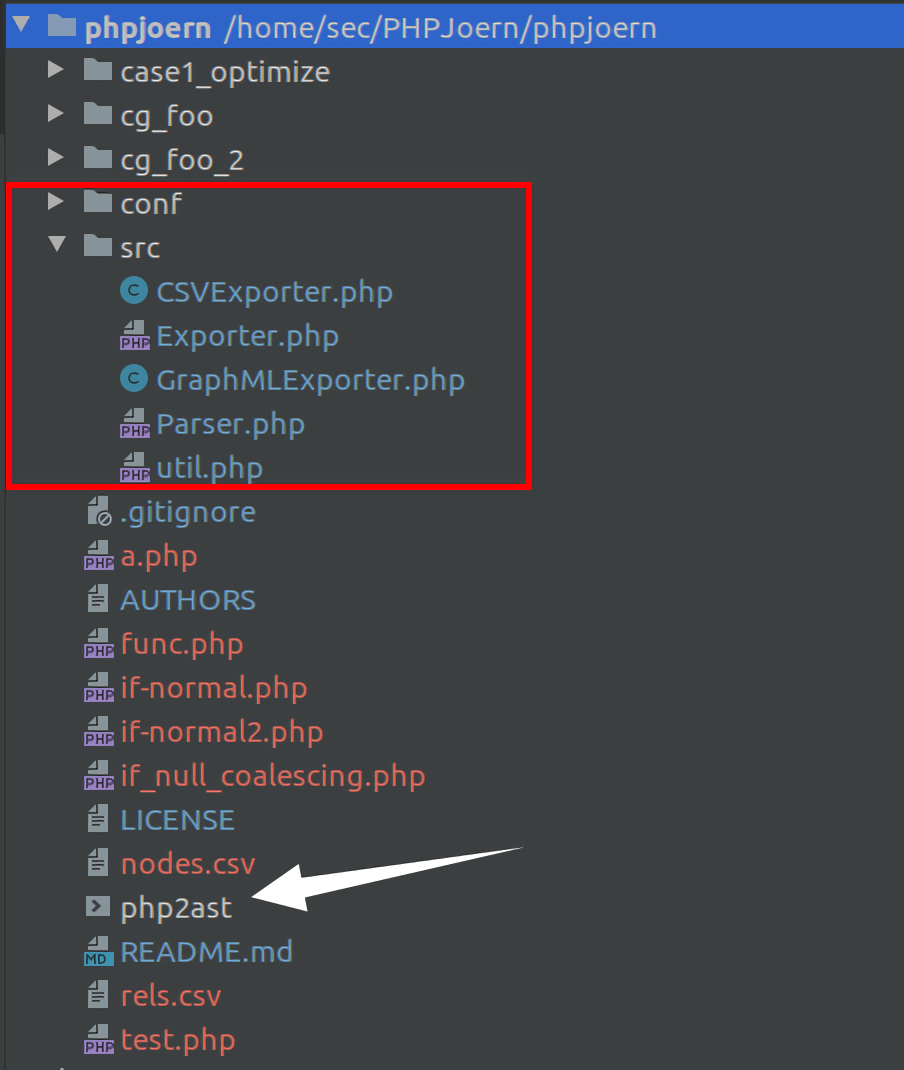
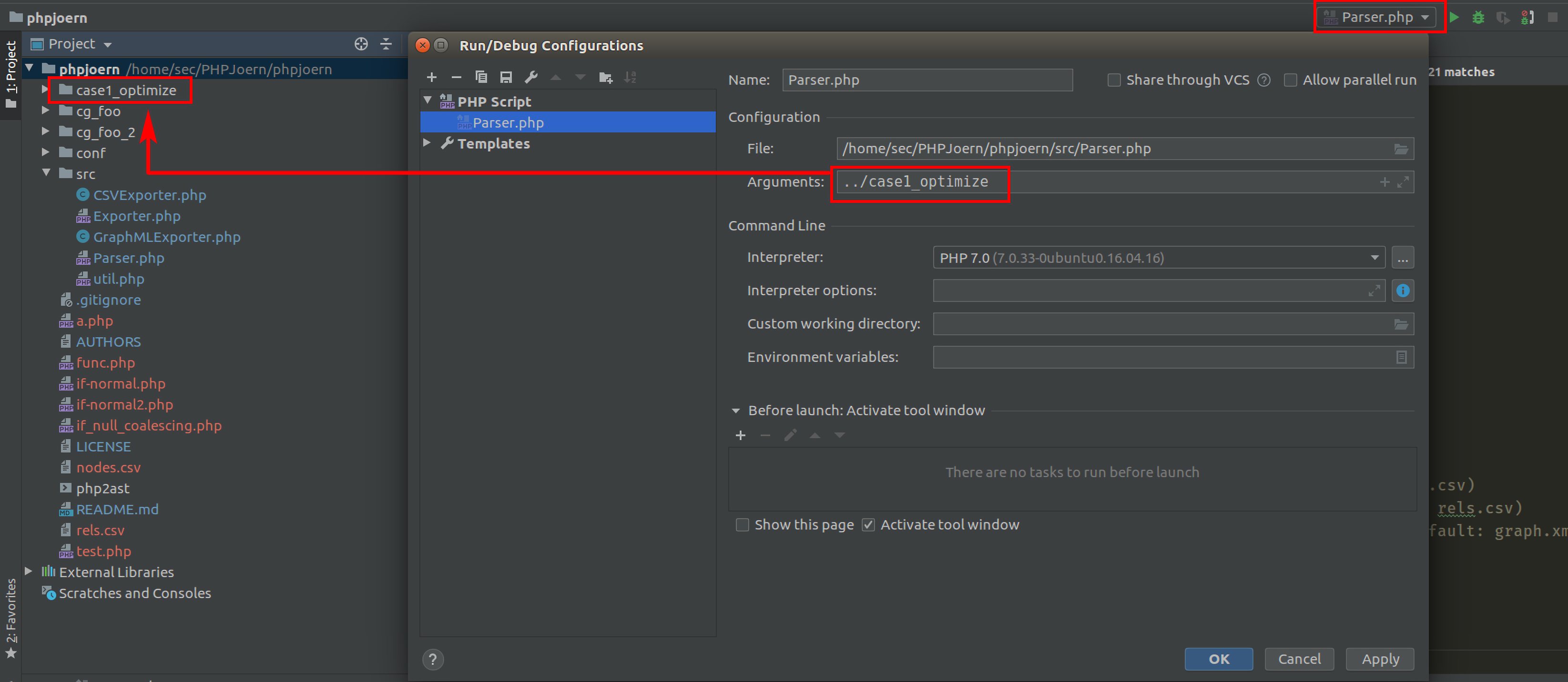
// 将要被解析的文件或者是目录 $path = null; // file/folder to be parsed $format = Exporter::JEXP_FORMAT; // format to use for export (default: jexp) $nodefile = CSVExporter::NODE_FILE; // name of node file when using CSV format (default: nodes.csv) $relfile = CSVExporter::REL_FILE; // name of relationship file when using CSV format (default: rels.csv) $outfile = GraphMLExporter::GRAPHML_FILE; // name of output file when using GraphML format (default: graph.xml) $scriptname = null; // this script's name $startcount = 0; // the start count for numbering nodes
/** * Parses the cli arguments. * 该函数的主要作用是检查命令行参数是否合法,比如参数数目是否正确之类的 * * @return Boolean that indicates whether the given arguments are * fine. */ functionparse_arguments(){
global $argv; if( !isset( $argv)) { if( false === (boolean) ini_get( 'register_argc_argv')) { error_log( '[ERROR] Please enable register_argc_argv in your php.ini.'); } else { error_log( '[ERROR] No $argv array available.'); } echo PHP_EOL; // PHP_EOL表示换行符\n returnfalse; }
// Remove the script name (first argument) global $scriptname; // [My Annotation]: array_shift() 函数删除数组中第一个元素,并返回被删除元素的值 // 所以array_shift() 函数会删除第一个参数,返回的参数为我们需要解析的文件名 $scriptname = array_shift( $argv);
// Set the path and remove from command line (last argument) global $path; // array_pop()和array_shift()的效果相反,返回 array 的最后一个值,并会弹出数组最后一个单元(出栈), // 即通过array_pop()可以获得需要解析的文件名 $path = (string) array_pop( $argv);
/** * Prints a usage message. */ functionprint_usage(){
global $scriptname; echo'Usage: php '.$scriptname.' [options] <file|folder>', PHP_EOL; }
/** * Prints a help message. */ functionprint_help(){
echo'Options:', PHP_EOL; echo' -h, --help Display help message', PHP_EOL; echo' -v, --version Display version information', PHP_EOL; echo' -f, --format <format> Format to use for the output files: "jexp" (default), "neo4j", or "graphml"', PHP_EOL; echo' -n, --nodes <file> Output file for nodes (for CSV output, i.e., neo4j or jexp modes)', PHP_EOL; echo' -r, --relationships <file> Output file for relationships (for CSV output, i.e., jexp or neo4j modes)', PHP_EOL; echo' -o, --out <file> Output file for entire graph (for XML output, i.e., graphml mode)', PHP_EOL; echo' -c, --count <number> Initial value of node counter (defaults to 0)', PHP_EOL; }
/** * Parses and generates an AST for a single file. * 为单个php文件解析ast * * @param $path Path to the file * @param $exporter An Exporter instance to use for exporting * the AST of the parsed file. * * @return The node index of the exported file node, or -1 if there * was an error. */ functionparse_file( $path, $exporter) : int{
$finfo = new SplFileInfo( $path); echo"Parsing file ", $finfo->getPathname(), PHP_EOL;
/** * Parses and generates ASTs for all PHP files buried within a * directory. * parse_dir()也还是通过parse_file()函数来解析单个文件的 * * @param $path Path to the directory * @param $exporter An Exporter instance to use for exporting * the ASTs of all parsed files. * @param $exporter 决定了ast是用什么格式导出的 * @param $top Boolean indicating whether this call * corresponds to the top-level call of the * function. We wouldn't need this if I didn't * insist on the root directory of a project * getting node index 0. But, I do insist. * @param $top top变量用来判定当前目录是否是最外层目录 * * @return If the directory corresponding to the function call finds * itself interesting, it stores a directory node for itself * and this function returns the index of that * node. Otherwise, returns -1. A directory finds itself * interesting if it contains PHP files, or if one of its * child directories finds itself interesting. -- As a special * case, the root directory of a project (corresponding to the * top-level call) always finds itself interesting and always * stores a directory node for itself. * @return 在没解析错误的情况下,最后的返回结果是当前遍历目录对应的目录节点id */ functionparse_dir( $path, $exporter, $top = true) : int{
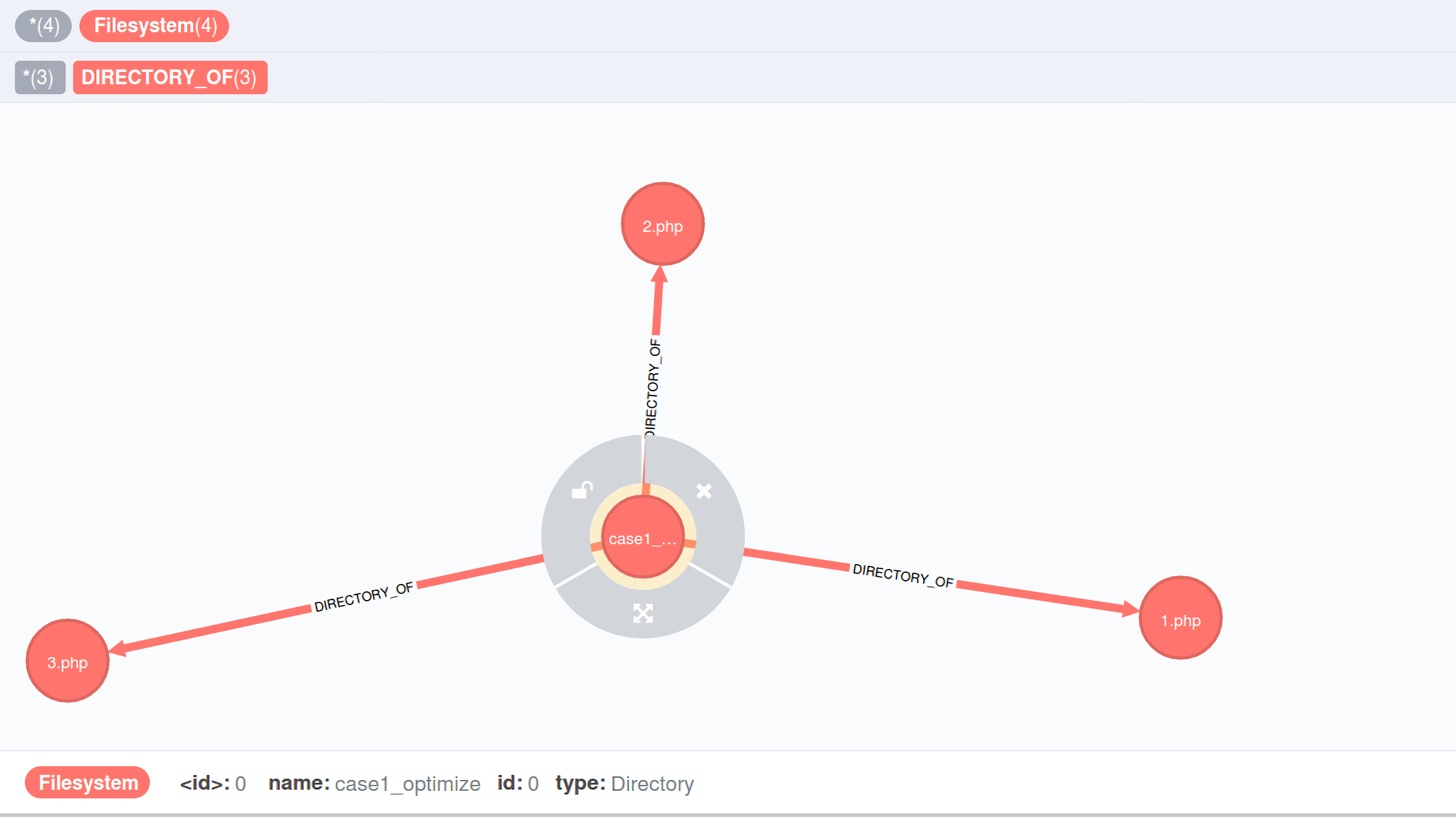
// save any interesting directory/file indices in the current folder $found = []; // if the current folder finds itself interesting, we will create a // directory node for it and return its index // 为最顶层目录也创建一个directory node,也是Filesystem,但是type=Directory,并且返回它对应id,一般情况下最顶层id=0 $dirnode = $top ? $exporter->store_dirnode( basename( $path)) : -1;
// iterate over everything in the current folder /** * readdir()函数:返回目录中下一个文件的文件名。文件名以在文件系统中的排序返回 * @return string|false the filename on success or false on failure. * 返回值:成功则返回文件名 或者在失败时返回 false */ // 循环遍历目录下的内容 while( false !== ($filename = readdir( $dhandle))) { /** * SplFileInfo: * The SplFileInfo class offers a high-level object oriented interface to information for an individual file. * SplFileInfo类是为单个文件的信息提供高级面向对象的接口,它可以用来获取文件详细信息 */ $finfo = new SplFileInfo( build_path( $path, $filename));
/** * Builds a file path with the appropriate directory separator. * * @param ...$segments Unlimited number of path segments. * * @return The file path built from the path segments. */ functionbuild_path( ...$segments){
// Check that source exists and is readable // 然后检查文件是否存在,存在的情况下是否可读,如果不存在或是不可读,exit if( !file_exists( $path) || !is_readable( $path)) { error_log( '[ERROR] The given path does not exist or cannot be read.'); exit( 1); }
$exporter = null; // Determine whether source is a file or a directory // 判断需要解析的文件是单文件还是目录 if( is_file( $path)) { try { if( $format === Exporter::GRAPHML_FORMAT) // 确定用什么格式来导出ast,GraphML format有很多工具支持 $exporter = new GraphMLExporter( $outfile, $startcount); else// either NEO4J_FORMAT or JEXP_FORMAT $exporter = new CSVExporter( $format, $nodefile, $relfile, $startcount); /** * 导出格式为NEO4J_FORMAT,neo4j-import工具可用 * 导出格式为JEXP_FORMAT,batch-import工具可用 */ } catch( IOError $e) { error_log( "[ERROR] ".$e->getMessage()); exit( 1); } parse_file( $path, $exporter); } elseif( is_dir( $path)) { try { if( $format === Exporter::GRAPHML_FORMAT) $exporter = new GraphMLExporter( $outfile, $startcount); else// either NEO4J_FORMAT or JEXP_FORMAT $exporter = new CSVExporter( $format, $nodefile, $relfile, $startcount); } catch( IOError $e) { error_log( "[ERROR] ".$e->getMessage()); exit( 1); } // 解析目录 parse_dir( $path, $exporter); } else { error_log( '[ERROR] The given path is neither a regular file nor a directory.'); exit( 1); }
// Check that source exists and is readable // 然后检查文件是否存在,存在的情况下是否可读,如果不存在或是不可读,exit if( !file_exists( $path) || !is_readable( $path)) { error_log( '[ERROR] The given path does not exist or cannot be read.'); exit( 1); }
$exporter = null; // Determine whether source is a file or a directory // 判断需要解析的文件是目录还是单一文件 if( is_file( $path)) { try { if( $format === Exporter::GRAPHML_FORMAT) $exporter = new GraphMLExporter( $outfile, $startcount); else// either NEO4J_FORMAT or JEXP_FORMAT $exporter = new CSVExporter( $format, $nodefile, $relfile, $startcount); } catch( IOError $e) { error_log( "[ERROR] ".$e->getMessage()); exit( 1); } parse_file( $path, $exporter); } elseif( is_dir( $path)) { try { if( $format === Exporter::GRAPHML_FORMAT) $exporter = new GraphMLExporter( $outfile, $startcount); else// either NEO4J_FORMAT or JEXP_FORMAT $exporter = new CSVExporter( $format, $nodefile, $relfile, $startcount); } catch( IOError $e) { error_log( "[ERROR] ".$e->getMessage()); exit( 1); } // 解析目录 parse_dir( $path, $exporter); } else { error_log( '[ERROR] The given path is neither a regular file nor a directory.'); exit( 1); }
// save any interesting directory/file indices in the current folder $found = []; // if the current folder finds itself interesting, we will create a // directory node for it and return its index // 为最顶层目录也创建一个directory node,也是Filesystem,但是type=Directory,并且返回它对应id,一般情况下最顶层id=0 $dirnode = $top ? $exporter->store_dirnode( basename( $path)) : -1;
// iterate over everything in the current folder /** * readdir()函数:返回目录中下一个文件的文件名。文件名以在文件系统中的排序返回 * @return string|false the filename on success or false on failure. * 返回值:成功则返回文件名 或者在失败时返回 false */ // 循环遍历目录下的内容 while( false !== ($filename = readdir( $dhandle))) { /** * SplFileInfo: * The SplFileInfo class offers a high-level object oriented interface to information for an individual file. * SplFileInfo类是为单个文件的信息提供高级面向对象的接口,它可以用来获取文件详细信息 */ $finfo = new SplFileInfo( build_path( $path, $filename));
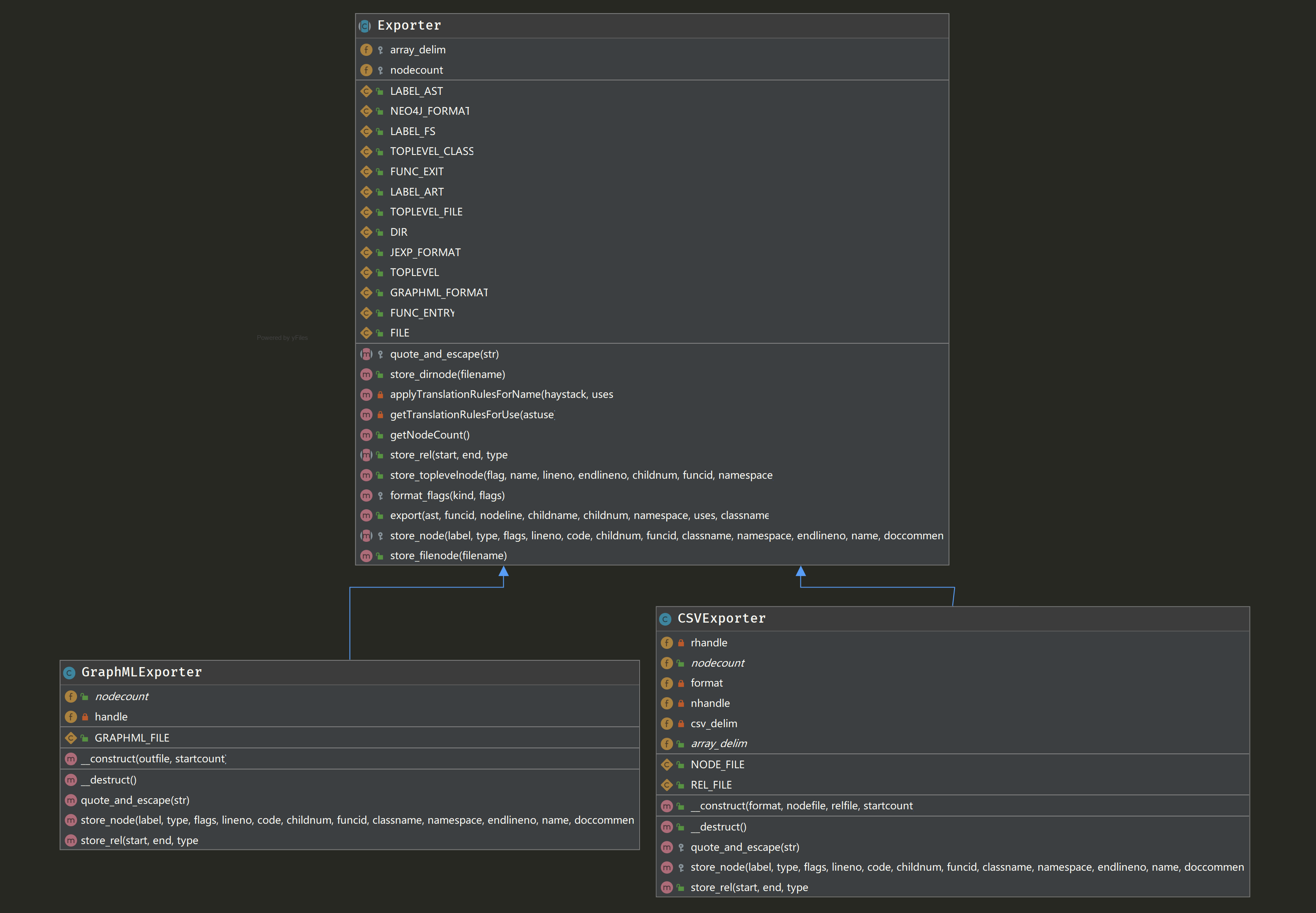
/** Constant for Neo4J format (to be used with neo4j-import) */ const NEO4J_FORMAT = 0; /** Constant for jexp format (to be used with batch-import) */ const JEXP_FORMAT = 1; /** Constant for GraphML format (supported by many tools) */ const GRAPHML_FORMAT = 2;
// For toplevel nodes, we create artificial entry and exit nodes (like file and dir nodes, // they are not actually part of the AST). // For the entry and exit nodes, we only set // (1) the funcid (to the id of the toplevel node), and // (2) the name (to that of the file or class) /** * 在处理了toplevel节点(toplevel节点是AST类型的)之后,还会处理两个artificial节点,分别是entry node和exit node * 一个Artificial节点存储的信息是这样的: name: case1_optimize/1.php id: 4 type: CFG_FUNC_EXIT funcid: 2 * type分别为self::FUNC_ENTRY和self::EXIT * name是文件名 * funcid比较特殊,是其toplevel节点的id */ $entrynode = $this->store_node( self::LABEL_ART, self::FUNC_ENTRY, null, null, null, null, $tnode, null, null, null, $this->quote_and_escape( $name), null); $exitnode = $this->store_node( self::LABEL_ART, self::FUNC_EXIT, null, null, null, null, $tnode, null, null, null, $this->quote_and_escape( $name), null); // 将toplevel节点 和entry节点 的关系边连起来,关系是ENTRY $this->store_rel( $tnode, $entrynode, "ENTRY"); // 将toplevel节点 和exit节点 的关系边连起来,关系是EXIT $this->store_rel( $tnode, $exitnode, "EXIT");
// (1) if $ast is an AST node, print info and recurse // An instance of ast\Node declares: // $kind (integer, name can be retrieved using ast\get_kind_name()) // $flags (integer, corresponding to a set of flags for the current node) // $lineno (integer, starting line number) // $children (array of child nodes) // Additionally, an instance of the subclass ast\Node\Decl declares: // $endLineno (integer, end line number of the declaration) // $name (string, the name of the declared function/class) // $docComment (string, the preceding doc comment) // 首先处理最普遍的情况:当前节点是AST类型的 if( $ast instanceof ast\Node) {
/** * function get_kind_name(int $kind): string {} * @param int $kind AST_* constant value defining the kind of an AST node * @return string String representation of AST kind value * 该函数会根据$kind值返回一个string, 该string对应特定的type,即$kind是和type对应的 */ $nodetype = ast\get_kind_name( $ast->kind); $nodeline = $ast->lineno;
$nodeflags = ""; /** * function kind_uses_flags(int $kind): bool {} * @param int $kind AST_* constant value defining the kind of an AST node * @return bool Returns true if AST kind uses flags * 判定某个AST_*类型是否有flags标志位,比如AST_NAME就有flags标志位,如NAME_NOT_FQ, NAME_FQ */ if( ast\kind_uses_flags( $ast->kind)) { $nodeflags = $this->format_flags( $ast->kind, $ast->flags); }
// store node, export all children and store the relationships $rootnode = $this->store_node( self::LABEL_AST, $nodetype, $nodeflags, $nodeline, null, $childnum, $funcid, $classname, $this->quote_and_escape( $namespace), $nodeendline, $nodename, $nodedoccomment);
// If this node is a function/method/closure declaration, set $funcid. // Note that in particular, the decl node *itself* does not have $funcid set to its own id; // this is intentional. The *declaration* of a function/method/closure itself is part of the // control flow of the outer scope: e.g., a closure declaration is part of the control flow // of the function it is declared in, or a function/method declaration is part of the control flow // of the pseudo-function representing the top-level code it is declared in. // Note: we do not need to do this for TOPLEVEL types (and it wouldn't be straightforward since we // do not generate ast\Node objects for them). Rather, for toplevel nodes under files, the funcid is // set by the Parser class, which also stores the File node; and for toplevel nodes under classes, // we do it below, while iterating over the children. // Also, we create artificial entry and exit nodes for the CFG of the function (like file and dir nodes, // they are not actually part of the AST). // For the entry and exit nodes, we only set // (1) the funcid (to the id of the function node), and // (2) the name (to that of the function) if( $ast->kind === ast\AST_FUNC_DECL || $ast->kind === ast\AST_METHOD || $ast->kind === ast\AST_CLOSURE) { $funcid = $rootnode; $entrynode = $this->store_node( self::LABEL_ART, self::FUNC_ENTRY, null, null, null, null, $rootnode, $classname, $this->quote_and_escape( $namespace), null, $this->quote_and_escape( $nodename), null); $exitnode = $this->store_node( self::LABEL_ART, self::FUNC_EXIT, null, null, null, null, $rootnode, $classname, $this->quote_and_escape( $namespace), null, $this->quote_and_escape( $nodename), null); $this->store_rel( $rootnode, $entrynode, "ENTRY"); $this->store_rel( $rootnode, $exitnode, "EXIT"); }
// If this node is a class declaration, set $classname // 如果当前节点是class声明,那么记录$classname if( $ast->kind === ast\AST_CLASS) { $classname = $nodename; }
// iterate over the children and count them // 开始递归遍历子节点 $i = 0; foreach( $ast->children as $childrel => $child) {
// If we encounter a child node that is a namespace node, set the namespace for subtrees and upcoming sister nodes // Note that we do not care whether the non-bracketed syntax (second child of AST_NAMESPACE is null) // or the bracketed syntax (second child of AST_NAMESPACE is a statement) was used: // (1) if non-bracketed, the namespace must be set for all upcoming sister nodes until we encounter // the next AST_NAMESPACE // (2) if bracketed, the namespace in principle only holds for the subtree rooted in the second child // of AST_NAMESPACE (and should be set only for that subtree, but not for upcoming sister nodes); // however, in this case the next sister node (if it exists) *must* be another // AST_NAMESPACE node, according to PHP syntax (otherwise, a 'No code may exist outside of namespace {}' // fatal error would be thrown at runtime.) Hence, if the next sister node is an AST_NAMESPACE anyway, // the namespace will be set to something new once we finished off the subtree rooted in the // second child of the AST_NAMESPACE we encountered. if( $child->kind === ast\AST_NAMESPACE) { $namespace = $child->children["name"] ?? ""; $uses = []; // any namespace statement cancels all uses currently in effect }
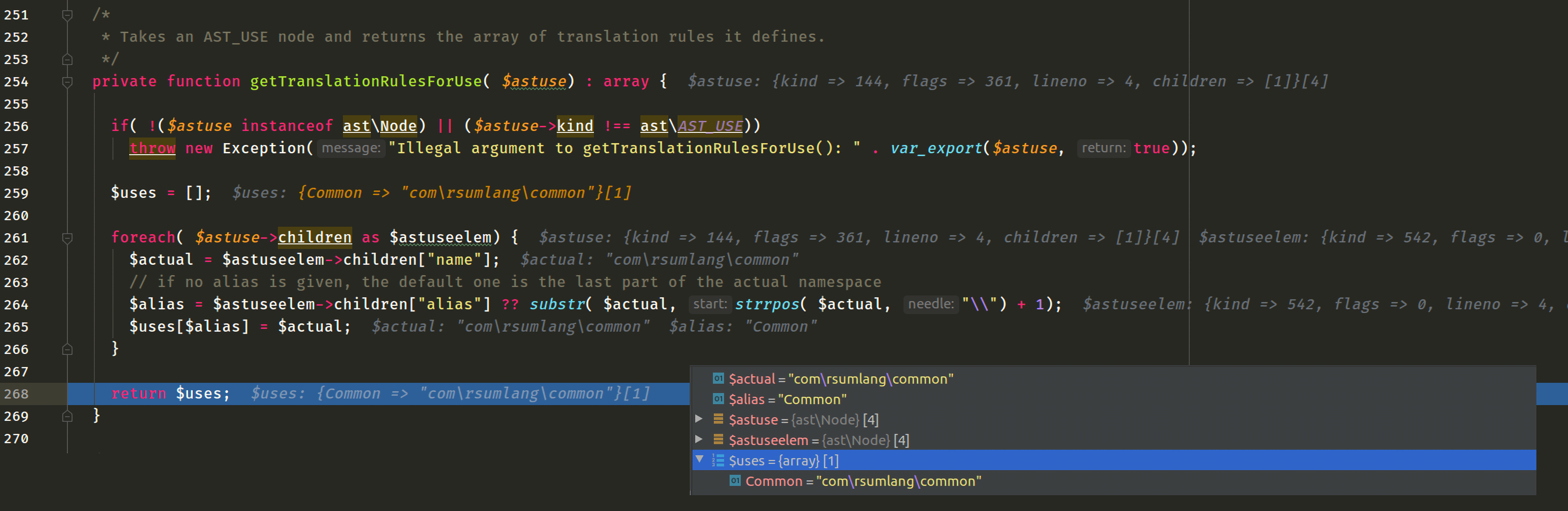
// If we encounter a child node that is a use node, add the translation rules specified by it // to the translation rules currently in effect if( $child->kind === ast\AST_USE) { $uses = array_merge( $uses, $this->getTranslationRulesForUse( $child)); }
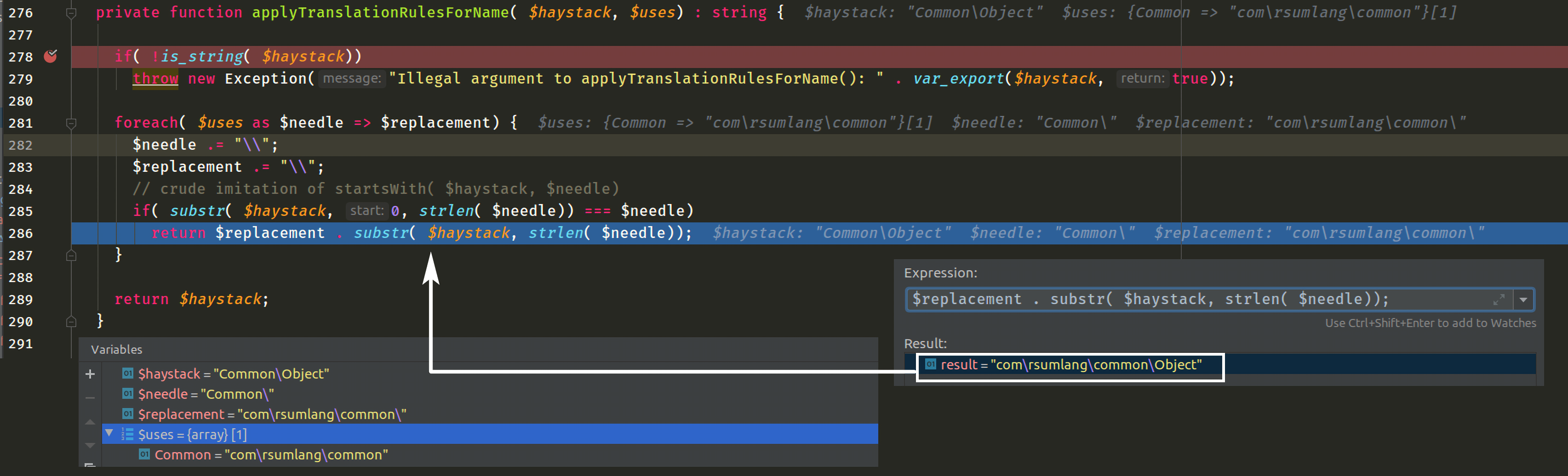
// for the "stmts" child of an AST_CLASS, which is an AST_STMT_LIST, // we insert an artificial toplevel function node if( $ast->kind === ast\AST_CLASS && $childrel === "stmts") { $tnode = $this->store_toplevelnode( Exporter::TOPLEVEL_CLASS, $nodename, $nodeline, $nodeendline, $i, $funcid, $namespace); // when exporting the AST_STMT_LIST below the AST_CLASS, the // funcid is set to the toplevel node's id, childname is set to "stmts" (doesn't really matter, we can invent a name here), and childnum is set to 0 // 递归遍历子节点 $childnode = $this->export( $child, $tnode, $nodeline, "stmts", 0, $namespace, $uses, $classname); $this->store_rel( $tnode, $childnode, "PARENT_OF"); // AST_TOPLEVEL -> AST_STMT_LIST $this->store_rel( $rootnode, $tnode, "PARENT_OF"); // AST_CLASS -> AST_TOPLEVEL } // for the child of an AST_NAME node which is *not* fully qualified, we apply the translation rules currently in effect elseif( $ast->kind === ast\AST_NAME && $childrel === "name" && $ast->flags !== ast\flags\NAME_FQ) { $child = $this->applyTranslationRulesForName( $child, $uses); // 递归遍历子节点 $childnode = $this->export( $child, $funcid, $nodeline, $childrel, $i, $namespace, $uses, $classname); $this->store_rel( $rootnode, $childnode, "PARENT_OF"); } // in all other cases, we simply recurse straightforwardly else { // 递归遍历子节点 $childnode = $this->export( $child, $funcid, $nodeline, $childrel, $i, $namespace, $uses, $classname); $this->store_rel( $rootnode, $childnode, "PARENT_OF"); }
foreach( $astuse->children as $astuseelem) { $actual = $astuseelem->children["name"]; // if no alias is given, the default one is the last part of the actual namespace /** * strrpos ( string $haystack , string $needle , int $offset = 0 ) : int * 计算指定字符串在目标字符串中最后一次出现的位置 */ // 如果use关键字没有使用 别名alias,那么就令actual namespace最后一个`\`后面的部分作为别名 // $uses[] 在后面的applyTranslationRulesForName()函数会用到 $alias = $astuseelem->children["alias"] ?? substr( $actual, strrpos( $actual, "\\") + 1); $uses[$alias] = $actual; }
/** * @param int $kind AST_* constant value defining the kind of an AST node * @return string String representation of AST kind value */ functionget_kind_name(int $kind): string{}
/** * @param int $kind AST_* constant value defining the kind of an AST node * @return bool Returns true if AST kind uses flags */ functionkind_uses_flags(int $kind): bool{}